为什么你的 AI Agent 总是"失忆"?OpenClaw 用两个文本文件解决了
你让 OpenClaw 帮你写了一个 API,调了三轮才满意。第二天你说”昨天那个 API 还需要加个分页”——它完全不记得了。
这是 AI Agent 最大的痛点之一:没有记忆,每次对话都从零开始。
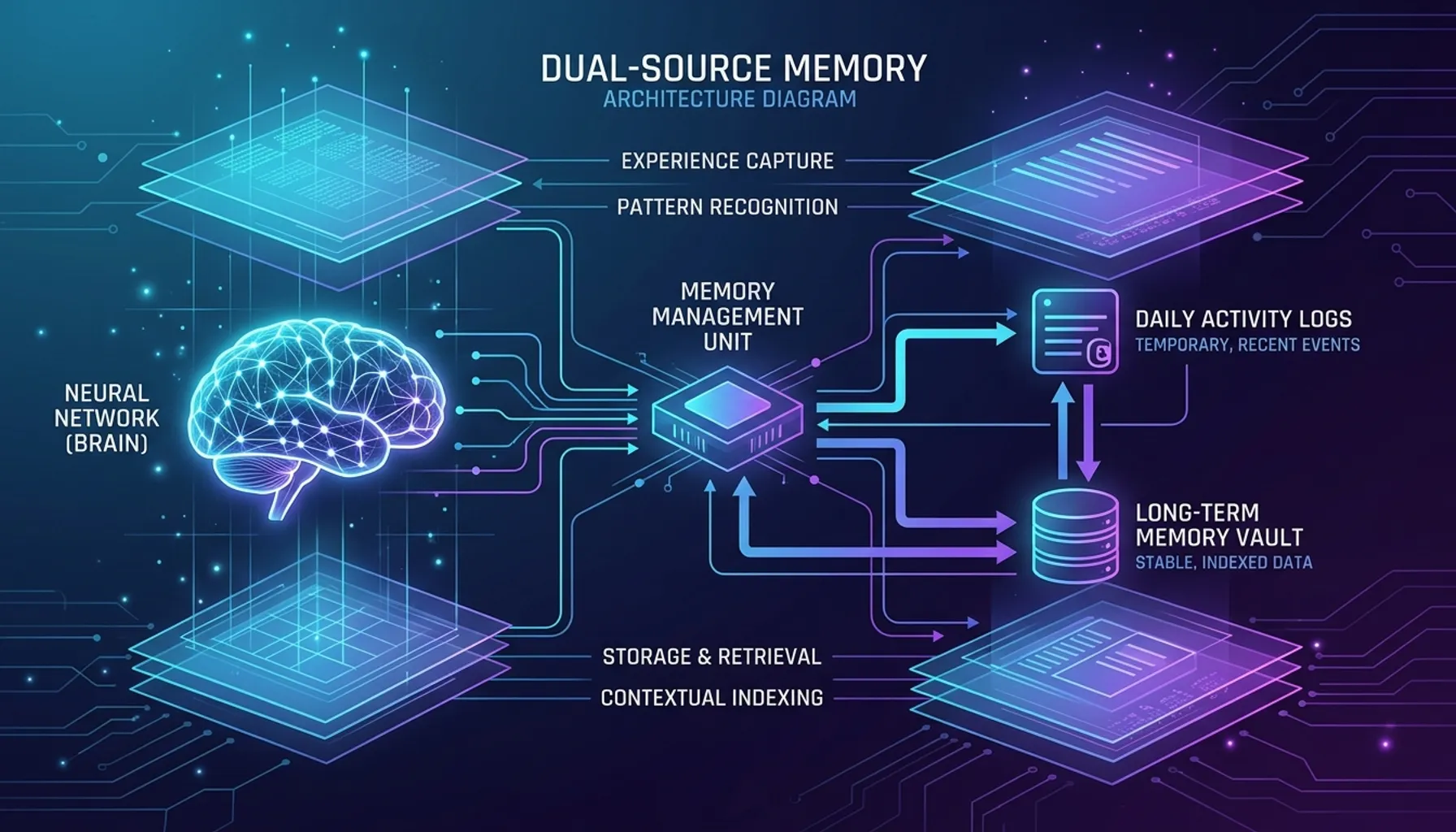
OpenClaw 的解决方案是一个叫做”双源记忆系统”的架构。两个独立的记忆源——长期记忆(MEMORY.md)和每日日志(daily logs)——协同工作,让 Agent 既能记住长期偏好,又能回忆昨天的工作细节。
这套系统在 2026 年初的 v0.5 版本中引入,3 月 7 日的 v2026.3.7-beta.1 又通过 ContextEngine 插件接口进行了重大升级。社区里有人说:**”这是 OpenClaw 和其他 Agent 框架拉开差距的关键设计。”**
今天我们从架构到代码,完整拆解这套双源记忆系统。
为什么需要”双源”:单一记忆的困境
在聊架构之前,先理解一个问题:为什么不用一个记忆源?
纯长期记忆的问题: 如果只有一个长期知识库,每次对话的临时信息——“刚才那个变量叫 userCount”、”上一轮我们决定用 PostgreSQL”——要么不存,要么全存。不存就丢失上下文,全存就把知识库变成垃圾场。
纯短期日志的问题: 如果只有逐日记录,Agent 知道你昨天做了什么,但不知道你”永远偏好 TypeScript 而不是 JavaScript”。每次都得重新告诉它你的偏好。
双源的设计哲学: 长期记忆存”你是谁、你喜欢什么、项目的核心约定”,每日日志存”今天做了什么、遇到了什么问题、决定了什么方案”。一个管身份,一个管经历。像人脑的语义记忆和情景记忆。
这不是 OpenClaw 发明的概念,但它的实现方式——纯文本文件 + 向量索引 + 混合搜索——在工程上非常优雅。
第一源:MEMORY.md——Agent 的”性格档案”
MEMORY.md 是 OpenClaw 的长期记忆文件,存在项目根目录下。它是一个纯 Markdown 文件,Agent 可以读,也可以写。
一个典型的 MEMORY.md 长这样:
1 | # User Preferences |
几个设计要点:
第一,纯文本,人类可读可编辑。 不是数据库,不是 JSON,是你用任何文本编辑器都能打开的 Markdown。这意味着你可以随时手动修改 Agent 的”记忆”——加一条偏好,删一条过时的信息。
第二,Agent 自主维护。 OpenClaw 的 Agent 在对话过程中会自动判断哪些信息值得写入 MEMORY.md。你说”以后别用 Jest 了,换成 Vitest”,它会把这条偏好追加到文件里。下次对话,它读到这条,就知道该用 Vitest。
第三,每次对话开始时自动加载。 Agent 启动时,MEMORY.md 的内容会被注入到系统提示词(system prompt)中。这相当于 Agent 的”人格初始化”——它一醒来就知道自己该怎么行事。
第四,有容量限制。 MEMORY.md 不能无限膨胀。OpenClaw 建议控制在 200 行以内,超过部分会被截断。这迫使你和 Agent 一起维护这个文件的质量——只保留真正重要的信息。
第二源:每日日志——Agent 的”工作日记”
每日日志存在 .openclaw/logs/ 目录下,文件名是日期:2026-03-19.md、2026-03-18.md……
每个日志文件记录了当天的对话摘要、关键决策、遇到的问题和解决方案。格式大概是这样的:
1 | # 2026-03-19 |
和 MEMORY.md 不同,每日日志有几个独特特性:
第一,自动生成,无需手动维护。 每轮对话结束时,Agent 会自动把关键信息压缩成摘要,追加到当天的日志文件里。你不需要操心。
第二,有时间维度。 你可以问 Agent:”上周三我们做了什么?”它会去查 2026-03-12.md,给你一个精确的回答。这是 MEMORY.md 做不到的——长期记忆没有时间概念。
第三,天然支持渐进式遗忘。 越早的日志,被检索到的概率越低。OpenClaw 的搜索算法会给近期日志更高的权重。这模拟了人类记忆的”近因效应”——昨天的事比上个月的事记得更清楚。
核心引擎:混合搜索
两个记忆源存了数据,但怎么找到需要的信息?这就是 OpenClaw 混合搜索引擎的工作。
当 Agent 需要回忆某些信息时,它调用内置的 memorySearch 工具。这个工具同时执行两种搜索:
向量搜索(Vector Search): 把查询文本转成嵌入向量,和记忆库中的向量做余弦相似度比较。适合语义匹配——你问”之前怎么处理认证的”,它能匹配到”JWT stored in httpOnly cookie”,即使两句话没有任何相同的词。
关键词搜索(BM25): 传统的全文检索。适合精确匹配——你问”Prisma 连接池”,它能直接找到包含这两个词的日志条目。
两种搜索的结果会被合并、去重、排序,返回最相关的记忆片段。
技术实现上:
存储层:SQLite + 向量扩展。 OpenClaw 用 SQLite 作为本地向量数据库。每条记忆被切分成约 400 Token 的 chunk,80 Token 重叠,用 SHA-256 做去重。这意味着同一段信息不会被重复索引。
嵌入模型:可插拔。 默认使用 OpenAI 的 text-embedding-3-small,但也支持 Gemini、Voyage、甚至本地模型。你可以在 settings.json 里配置:
1 | { |
搜索权重:可调节。 向量搜索和 BM25 的权重比默认是 0.7:0.3。如果你的使用场景更偏精确查找(比如代码片段检索),可以把 BM25 的权重调高。
关键机制:Pre-Compaction Flush
双源记忆系统里最精巧的设计,是 pre-compaction flush(压缩前刷写)机制。
什么是 compaction?当对话上下文太长时,OpenClaw 会对早期消息做摘要压缩,释放上下文窗口空间。这个过程叫 compaction。
问题来了:如果一段重要的对话在 compaction 时被压缩了,细节就丢失了。摘要只保留大意,不保留具体的代码片段、参数值、配置项。
Pre-compaction flush 的解决方案: 在 compaction 执行之前,先把即将被压缩的对话内容写入记忆系统。具体流程是:
- 检测到上下文即将溢出,触发 compaction
- 暂停压缩,先执行 flush
- 把即将被压缩的消息中的关键信息提取出来
- 写入每日日志(短期)和/或 MEMORY.md(长期)
- 建立向量索引
- 恢复压缩,对原始消息做摘要
这样,即使对话被压缩了,关键信息已经安全地存到了记忆系统里。Agent 以后可以通过 memorySearch 检索到这些信息。
社区的评价是:**”这个 flush-before-discard 模式解决了所有 Agent 框架都面临的上下文丢失问题。”**
ContextEngine:插件化的记忆架构
2026 年 3 月 7 日,OpenClaw v2026.3.7-beta.1 引入了 ContextEngine 插件接口。这是双源记忆系统的一次重大升级。
ContextEngine 定义了五个生命周期钩子:
| 钩子 | 触发时机 | 用途 |
|---|---|---|
bootstrap |
Agent 启动时 | 加载初始记忆、建立索引 |
ingest |
新消息到达时 | 提取信息、判断是否值得记忆 |
assemble |
构建上下文时 | 决定哪些记忆注入到当前对话 |
compact |
上下文压缩时 | 执行 pre-compaction flush |
afterTurn |
每轮对话结束后 | 更新日志、维护索引 |
这意味着你可以写自定义的 ContextEngine 插件,完全改变 Agent 的记忆行为。
比如,你可以写一个插件,让 Agent 把记忆存到 Notion 而不是本地文件。或者写一个插件,让 Agent 根据项目的 Git 历史自动构建上下文——谁改了什么文件、什么时候改的、commit message 写了什么。
36 氪的评价是:**”ContextEngine 把 OpenClaw 从一个’带记忆的 Agent’变成了一个’记忆架构可编程的 Agent 平台’。”**
实战:怎么用好双源记忆
理解了架构,来聊聊实战中怎么用好这套系统。
技巧 1:主动维护 MEMORY.md。 不要完全依赖 Agent 自动写入。定期检查 MEMORY.md,删掉过时的信息,补充遗漏的偏好。一个干净的 MEMORY.md 比一个臃肿的 MEMORY.md 效果好 10 倍。
技巧 2:用 memorySearch 调试记忆。 如果 Agent 的行为不符合预期,直接问它:”搜索你的记忆,关于 X 你记得什么?”看看返回的结果是否正确。很多时候问题不是 Agent 笨,而是记忆库里存了错误的信息。
技巧 3:利用日志做复盘。 每日日志不只是给 Agent 用的,你自己也可以看。cat .openclaw/logs/2026-03-19.md 就能看到今天所有的对话摘要。这是一个天然的工作日报。
技巧 4:为团队项目配置共享记忆。 把 MEMORY.md 提交到 Git 仓库里。团队成员的 Agent 都能读到同样的项目约定。这比口头传达”我们项目用 Vitest 不用 Jest”高效得多。
和其他 Agent 框架的记忆方案对比
OpenClaw 不是唯一做记忆系统的。简单对比:
| 框架 | 记忆方案 | 特点 |
|---|---|---|
| OpenClaw | 双源(MEMORY.md + 日志) | 纯文本、人类可编辑、混合搜索 |
| Claude Code | 文件记忆(~/.claude/memory/) | 结构化文件、MEMORY.md 索引、项目隔离 |
| Cursor | 对话摘要 + .cursorrules | 无持久化日志,依赖规则文件 |
| AutoGPT | 向量数据库(Pinecone/Weaviate) | 纯向量,无人类可读层 |
| LangChain Memory | ConversationBufferMemory | 内存级,进程退出即丢失 |
OpenClaw 的独特之处在于两层都是人类可读的纯文本。你不需要数据库客户端就能查看和修改 Agent 的全部记忆。这在调试和审计时价值巨大。
AutoGPT 的纯向量方案搜索能力更强,但你无法直接阅读”Agent 到底记住了什么”。LangChain 的内存方案最简单,但不支持跨会话持久化。
局限和未来方向
诚实说,双源记忆系统也有局限。
第一,记忆质量依赖 Agent 的判断。 Agent 决定”什么值得记住”。如果它判断失误——把重要信息忘了,或者把噪音当成知识存下来——记忆库的质量就会下降。目前没有自动清理过时记忆的机制。
第二,向量搜索有成本。 每次 memorySearch 都要调用嵌入模型 API。如果记忆库很大(数百条记录),每次搜索的 Token 消耗不可忽略。
第三,多 Agent 协作场景不够成熟。 当多个 Agent 同时读写同一个 MEMORY.md 时,可能出现冲突。ContextEngine 的 ingest 钩子没有提供锁机制。
社区里讨论最多的下一步是记忆的自动衰减和整理——让 Agent 定期回顾自己的记忆,合并重复项,淘汰过时信息。就像人脑在睡眠时整理白天的记忆一样。
写在最后
记忆是 AI Agent 从”工具”变成”助手”的分水岭。
没有记忆的 Agent,每次对话都是初次见面。有了记忆,它知道你的偏好、你的项目、你昨天做了什么、你上周为什么改变了方案。
OpenClaw 的双源记忆系统不是最复杂的方案,但可能是最务实的——纯文本文件保证了透明和可控,混合搜索保证了检索质量,pre-compaction flush 保证了信息不丢失,ContextEngine 保证了可扩展性。
当你的 Agent 开始记住你的名字、你的代码风格、你昨天犯的那个 bug——你和 AI 的关系就变了。 它不再是一个你每次都需要从头教的工具,而是一个越用越懂你的搭档。
这才是 Agent 时代真正让人兴奋的地方。
你在用 OpenClaw 的记忆系统吗?MEMORY.md 里你都写了什么?你觉得 AI Agent 应该记住你的哪些信息?欢迎在评论区聊聊你的记忆管理经验。