别再搞混了:Claude Code 的 Skill 和 MCP 是两种完全不同的东西
上周有个朋友问我:”我想让 Claude Code 在做代码审查的时候自动查 Sentry 的报错日志,我应该写一个 Skill 还是接一个 MCP?”
我反问他:”你想教 Claude 怎么做代码审查,还是想给 Claude 一个能查 Sentry 的工具?”
他愣了一下:”这……有区别吗?”
有。而且区别很大。
在 Claude Code 的生态里,Skill 和 MCP 是两个最容易被搞混的概念。很多人把它们当成同一种东西的不同写法。甚至有人在社区里问:”Skill 是不是要取代 MCP?”
答案是:不会。因为它们根本不是同一类东西。
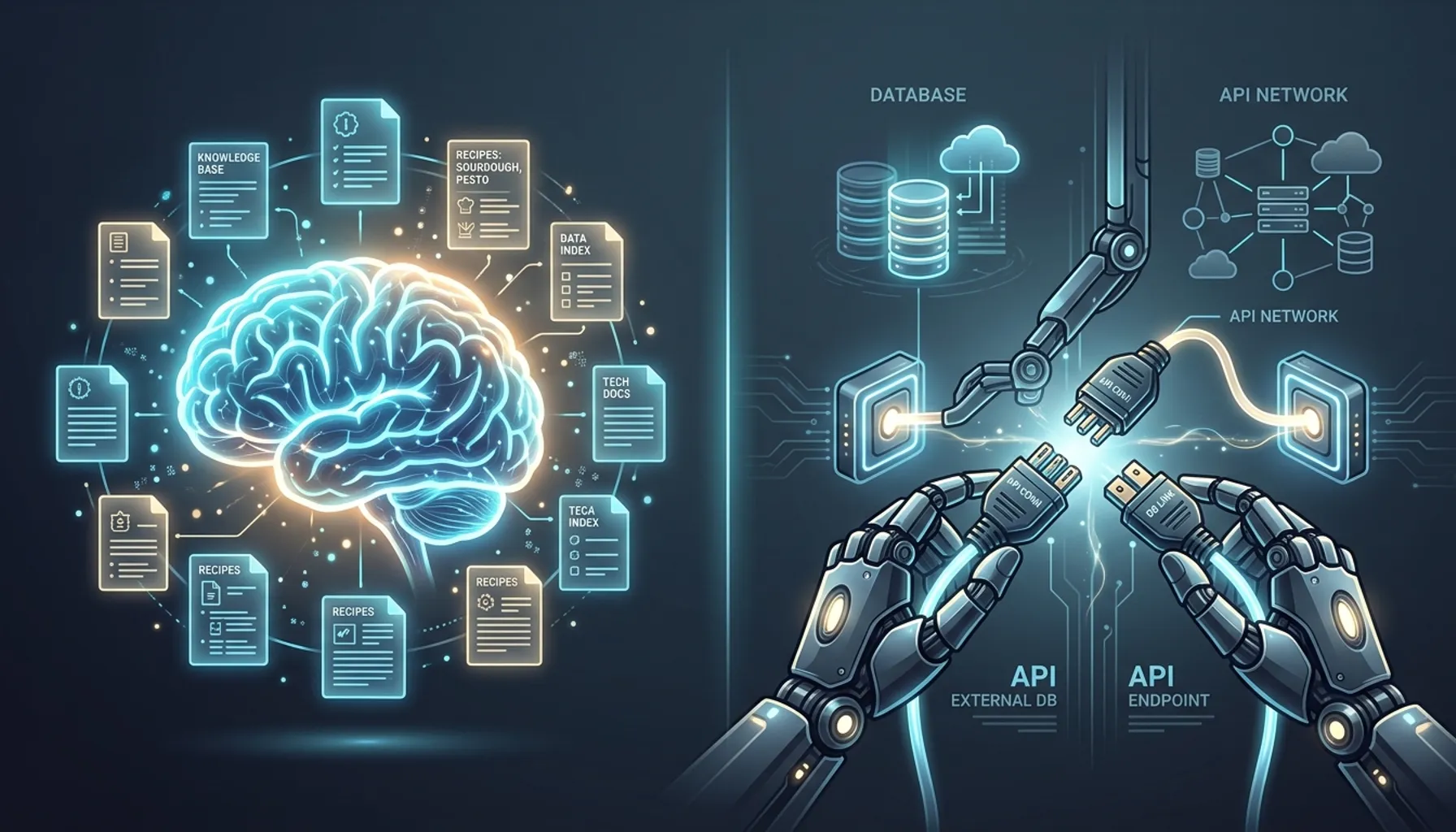
Towards Data Science 上有一个很精准的类比:MCP 是厨房——刀具、锅碗、食材。Skill 是菜谱——告诉你怎么用这些东西做出一道菜。
厨房和菜谱,缺一不可。但你不会把菜谱当刀用,也不会拿刀当菜谱读。
今天把这两个概念彻底说清楚。
Skill 是什么:写在 Markdown 里的”领域知识”
本质:高级 Prompt
Skill 的本质非常简单——它就是一个 Markdown 文件,里面写着一组结构化的指令。
当你创建一个 Skill,你在做的事情是:把你脑子里的专业知识、工作流程、判断标准,写成 Claude 能理解的文字。
比如你是一个前端团队的 Tech Lead。你的团队有自己的代码规范:组件用 PascalCase 命名,状态管理只用 Zustand,CSS 必须用 Tailwind,测试覆盖率不低于 80%。
每次有新人来,你都要花半天给他讲这些规范。每次 Claude 帮你写代码,你都要在 prompt 里重复一遍这些要求。
Skill 就是把这些”你每次都要说的话”固定下来,让 Claude 自动加载。
一个最简单的 Skill 长这样:
1 | --- |
没有代码。没有 API 调用。没有外部依赖。纯文字指令。
这就是 Skill 最核心的特征:它教 Claude **”怎么做”**,而不是给 Claude **”新能力”**。
Skill 的三层加载
Skill 有一个很聪明的设计——渐进式加载(Progressive Disclosure)。
Claude 不会一次性把所有 Skill 的内容塞进上下文窗口。它分三层:
第一层:元数据(始终加载)
只有名字和描述,大约 100 个 token。Claude 根据这个判断要不要激活这个 Skill。
第二层:SKILL.md 主体(触发时加载)
用户的请求匹配了 Skill 的描述,Claude 才会读取完整内容。
第三层:附属资源(按需加载)
scripts/、references/、assets/ 目录下的文件,只有 Claude 觉得需要的时候才会去读。
这意味着你可以装几十个 Skill,不用担心把上下文窗口撑爆。Claude 只在需要的时候才”翻开菜谱”。
Skill 的三种模式
根据复杂度,Skill 分三种模式:
模式 A:纯 Prompt
就是一个 Markdown 文件。适合编码规范、代码审查清单、commit message 格式化这类任务。Claude 的语言能力就足够完成。
模式 B:Prompt + 脚本
Markdown 指令加上 scripts/ 目录里的 Python 或 JavaScript 脚本。适合需要确定性计算的任务——数据验证、Excel 处理、报表生成。
模式 C:Prompt + MCP/子 Agent
在 Skill 的工作流中调用 MCP 服务器或子 Agent。适合涉及外部服务的复杂场景——比如创建 Issue → 建分支 → 修代码 → 提 PR。
注意模式 C:Skill 和 MCP 在这里是配合关系,不是替代关系。
MCP 是什么:连接外部世界的”标准插头”
本质:工具协议
MCP 的全称是 Model Context Protocol(模型上下文协议)。Anthropic 在 2024 年 11 月发布了它。
MCP 解决的问题和 Skill 完全不同。
Skill 解决的是”Claude 不知道怎么做”。MCP 解决的是”Claude 做不到”。
Claude 自己不能查 GitHub 的 PR。不能发 Slack 消息。不能连你的数据库。不能打开浏览器。
这些都不是”知识”问题,是”能力”问题。Claude 需要的不是一个菜谱,是一把刀。
MCP 就是那把刀。更准确地说,MCP 是一个标准化的接口协议,让 Claude 能够调用外部工具和访问外部数据。
它的架构是经典的客户端-服务器模型:
1 | Claude Code(客户端) |
每个 MCP Server 暴露一组”工具”(Tools)。Claude Code 在启动时自动发现这些工具,然后在需要的时候调用它们。
比如 GitHub MCP Server 暴露的工具包括:创建 PR、查看 Issue、合并分支。Brave Search MCP Server 暴露的工具是:搜索网页、搜索新闻、搜索图片。
MCP 不告诉 Claude 怎么做。它给 Claude 新的手和脚,让 Claude 能触达原本触达不到的地方。
MCP 的配置方式
MCP 的配置写在 .claude/settings.json 里:
1 | { |
每个 MCP Server 是一个独立运行的进程。Claude Code 通过 JSON-RPC 协议和它通信。支持三种传输模式:stdio(标准输入输出)、SSE(服务器推送事件)、HTTP Streamable。
关键区别来了:MCP Server 是一个运行中的服务。Skill 是一个静态的文件。
这是两者最本质的技术差异。
MCP 的生态规模
截至 2026 年 3 月,MCP 的生态已经相当庞大:
- 月 SDK 下载量超过 9700 万次
- 活跃的 MCP Server 超过 10000 个
- 支持的平台:Claude、ChatGPT、Cursor、Gemini、VS Code、Copilot
- 官方 SDK 覆盖 Python、TypeScript、C#、Java
Wikipedia 上把 MCP 比作”AI 的 USB-C”——一个标准接口,让任何 AI 都能连接任何工具。
一张表看清区别
| 对比维度 | Skill | MCP |
|---|---|---|
| 本质 | 结构化 Prompt(Markdown 指令) | 工具调用协议(JSON-RPC) |
| 解决的问题 | Claude 不知道”怎么做” | Claude “做不到” |
| 类比 | 菜谱 | 厨房里的刀具和食材 |
| 技术形态 | 静态 Markdown 文件 | 运行中的服务进程 |
| 存放位置 | .claude/skills/ 目录 |
.claude/settings.json 配置 |
| 外部依赖 | 无(纯文本即可) | 需要运行 MCP Server |
| 能否访问外部系统 | 不能(除非配合 MCP) | 能(这就是它的核心功能) |
| 上下文消耗 | 极小(渐进式加载) | 较大(但已优化) |
| 创建门槛 | 极低(写个 Markdown) | 中等(需要理解协议和配置) |
| 跨平台兼容 | Claude Code 生态 | 跨所有支持 MCP 的 AI 平台 |
一句话总结:Skill 教 Claude 领域知识,MCP 给 Claude 外部工具。
实战:它们怎么配合
回到开头那个问题:想让 Claude Code 在代码审查时自动查 Sentry 报错日志,该用 Skill 还是 MCP?
答案是:两个都要。
用 MCP 连接 Sentry——让 Claude 能调用 Sentry 的 API,查询项目的错误日志、异常堆栈、影响范围。
用 Skill 定义审查流程——告诉 Claude:先看代码变更,然后查 Sentry 是否有相关报错,重点关注错误频率和影响用户数,最后生成审查报告,格式要包含”风险等级、影响范围、修复建议”。
Sentry 官方就是这么做的。他们的代码审查 Skill 定义了 PR 分析工作流,同时通过 MCP 获取 Sentry 的错误数据。
再举几个例子:
场景 1:自动化部署
- MCP:连接 AWS / GCP 的部署 API
- Skill:定义部署流程——先跑测试,再构建镜像,最后灰度发布,每一步的检查标准是什么
场景 2:技术文档生成
- MCP:连接 GitHub 获取代码变更,连接 Confluence 发布文档
- Skill:定义文档模板和写作风格——API 文档要包含请求示例、返回格式、错误码说明
场景 3:数据分析报告
- MCP:连接数据库查询数据
- Skill:定义分析框架——先看整体趋势,再拆分维度,找到异常点,最后给出行动建议
模式很清楚:MCP 负责”拿到数据”,Skill 负责”怎么用数据”。
常见误区
误区 1:”Skill 会取代 MCP”
不会。Simon Willison 在 2025 年说 Skill 可能”比 MCP 更重要”,但开发者 Phil Whittaker 在深度对比后得出结论:它们解决的是完全不同的问题,互补而非竞争。
Skill 再强大,也不能帮 Claude 发一条 Slack 消息。MCP 再灵活,也不能教 Claude 你们团队的代码规范。
误区 2:”MCP 太重了,能用 Skill 替代就替代”
早期的 MCP 确实有上下文窗口消耗的问题——一个工具可能占 500-900 token,几十个工具就把窗口撑满了。
但 2026 年 1 月,Claude Code 给 MCP 也加上了渐进式发现(Progressive Discovery)。token 开销从 77000 降到了 8700,降了 85%。这个问题已经解决了。
误区 3:”我直接在 Skill 里写 API 调用代码不就行了”
技术上可以——Skill 支持 scripts/ 目录,你可以写 Python 脚本直接调用 API。
但 MCP 提供了标准化、权限管理、日志审计、跨平台兼容。如果你的团队明天从 Claude 换到 Codex,MCP Server 直接能用,Skill 里的脚本就得重写。
单人项目用 Skill 脚本没问题。团队协作和生产环境,MCP 是更稳妥的选择。
写在最后
Skill 和 MCP 的关系,本质上就是知识和工具的关系。
一个厨师光有一把好刀不够——他还需要知道食材的特性、火候的控制、调味的顺序。反过来,光背菜谱也不行——他得有刀、有锅、有灶台才能真的做出菜来。
Skill 是 Claude 的”大脑”——领域知识、工作流程、判断标准。
MCP 是 Claude 的”双手”——连接外部系统、获取数据、执行操作。
搞清楚这个区别,你才能真正用好 Claude Code 的扩展能力。需要教 Claude 怎么做?写 Skill。需要让 Claude 做到新的事情?接 MCP。需要两者配合?那就是最强大的组合。
你在用 Claude Code 的 Skill 还是 MCP?有没有遇到过”不知道该用哪个”的场景?你写过自己的 Skill 吗,效果如何?你觉得 Skill 和 MCP 未来会不会合并成一种东西?评论区聊聊你的使用经验。