Anthropic 的 Harness 到底是什么?一文看懂 AI 编程的「套娃」玩法
大家好,我是飞飞。
上周我在 GitHub Trending 上刷到一个项目,名字里带着 “harness”,5 万多 star。点进去一看,满屏都是 Skills、Hooks、Subagents 这些术语,我当时就懵了——这帮人到底在玩什么?
后来我花了两天时间,把 Anthropic 的两篇技术博客、Claude Code 官方文档、加上社区里几十个项目翻了一遍,终于搞明白了。
Harness 这个词,翻译成人话就是:怎么给 AI 编程助手套一个工作流,让它别瞎搞。
今天把我理解的东西分享出来。
先搞懂一个问题:AI 为什么需要 Harness?
想象一个场景。
你招了一个天才程序员,智商极高,代码写得又快又好。但有个问题——他每隔一段时间就会失忆,忘记之前做了什么。而且他容易兴奋,一上来就想把整个项目一口气写完,写到一半发现上下文不够了,代码就烂尾了。
更要命的是,你让他自己检查代码质量,他每次都说:”写得挺好的啊,没问题。”
这就是 AI 编程 Agent 面临的真实困境。
Harness 的本质,就是给这个天才程序员套一个工作流框架。 告诉他该怎么分步做事,什么时候该停下来检查,做完一步怎么把进度交接给下一步。
Harness 这个英文词,本意是马具——缰绳、马鞍那套东西。你不会让一匹马在公路上裸奔,AI Agent 也一样。
Anthropic 的 Harness 思路:从一篇论文到一套体系
Anthropic 在这个方向上发了两篇技术博客,我觉得思路特别值得学习。
第一篇:让 Agent 学会「接力赛跑」
第一篇叫《Effective Harnesses for Long-Running Agents》。
核心问题很直接:AI 的上下文窗口是有限的,一个复杂项目不可能在一个窗口里写完。怎么办?
Anthropic 的方案是设计两个角色:
- 初始化 Agent(Initializer):拿到用户需求后,先把项目拆成一个详细的功能清单(200+ 个小功能),搭好项目脚手架,写好启动脚本,建好 Git 仓库。
- 编码 Agent(Coding Agent):每次只做一个功能。做完提交代码,写好进度笔记,然后把接力棒交给下一个自己。
这就像一场接力赛。每个运动员跑一段,到了交接区把棒递给下一个人。关键是那根「接力棒」——一个叫 claude-progress.txt 的进度文件,加上 Git 提交记录。
如果你用过 Claude Code 做稍微复杂点的项目,下面这些场景你一定不陌生:
Agent 一上来就想把整个项目一口气写完,写到一半上下文爆了,代码烂尾。Anthropic 的解法是——强制它每次只做一个功能,做完提交,再做下一个。
做了三四个功能之后,Agent 突然说”项目已完成!”你一看,还有一大半没做呢。解法是维护一个 JSON 格式的功能清单,每个功能标记 true 或 false,没完成的白纸黑字摆在那儿,它想糊弄都糊弄不了。
上一轮 Agent 写到一半上下文就断了,下一轮新 Agent 一脸懵,不知道从哪接。解法是每轮结束必须提交 Git、写进度笔记到 claude-progress.txt——相当于交接班必须写交接报告。
第二篇:让 AI 学会「自我批评」
第二篇叫《Harness Design for Long-Running Apps》,更进了一步。
Anthropic 发现了一个有趣的现象:AI 不擅长评价自己的作品。你让它写完代码再自己打分,它每次都说”还不错”。就像让学生自己批改考卷一样——分数永远虚高。
怎么办?借鉴 GAN(生成对抗网络)的思路,搞一个「生成者 + 评估者」的对抗机制:
- 规划 Agent(Planner):把一句话需求扩展成完整的产品规格书。
- 生成 Agent(Generator):负责写代码,一个功能一个功能地实现。
- 评估 Agent(Evaluator):用 Playwright 浏览器自动化工具,像真实用户一样点击、测试、截图,然后打分写报告。
评估 Agent 不是随便打分,它有四个明确的评估维度:
- 设计质量:界面是不是有整体感,还是拼凑出来的?
- 原创性:有没有自己的设计决策,还是全是 AI 默认模板?
- 工艺水平:字体、间距、颜色搭配是否专业?
- 功能性:用户能不能顺畅地完成任务?
Anthropic 用这套架构做了一个实验:让 AI 生成一个荷兰艺术博物馆网站。前 9 轮迭代,输出还是常规操作——黑色主题,整洁的卡片布局。但到了第 10 轮,AI 突然「开窍」了,把整个网站改成了一个 3D 空间体验:有棋盘格地板、画作挂在墙上、通过「门廊」在不同展厅之间导航。
这种创造性的跳跃,在没有 Harness 的单次生成中从未出现过。
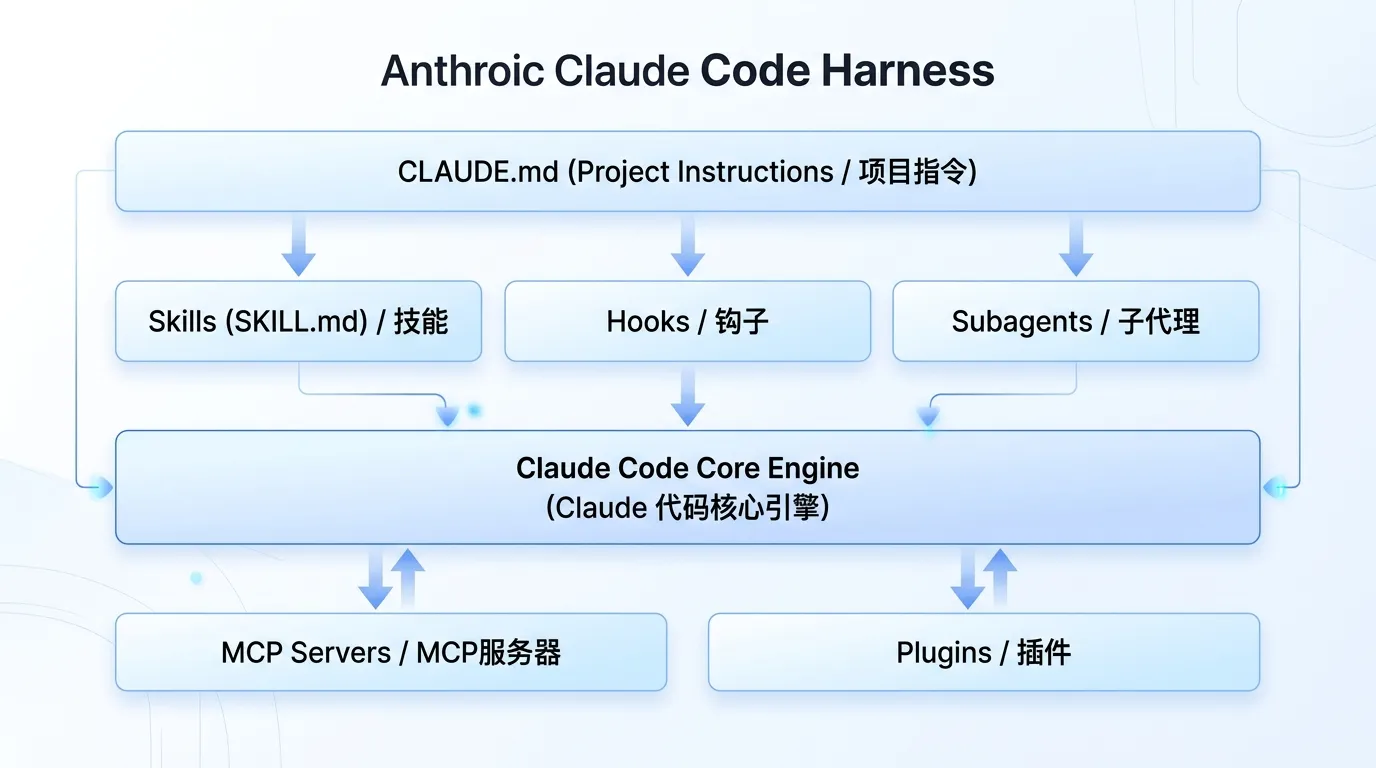
落地到 Claude Code:一套完整的扩展体系
说完理论,来看 Claude Code 实际给我们提供了哪些工具。
CLAUDE.md:项目的「说明书」
每个项目根目录放一个 CLAUDE.md 文件,Claude Code 每次启动都会自动读取。
我最开始用 Claude Code 的时候,压根不知道这东西的存在。直到有一次它把我 Hexo 博客的配置改得面目全非,我才意识到:不立规矩,它就按自己的理解来。
后来我在 CLAUDE.md 里写清楚了项目架构、代码规范、哪些文件不能动,效果立竿见影。
1 | # CLAUDE.md |
有个建议:控制在 200 行以内。我见过有人写了 2000 行的 CLAUDE.md,结果 Claude 反而更懵了——信息太多等于没有信息。
Skills:按需加载的「技能包」
Skills 是 Claude Code 最核心的扩展机制。
每个 Skill 就是一个文件夹,里面放一个 SKILL.md,描述清楚:什么时候触发、该执行什么步骤、用到哪些工具。
1 | .claude/skills/ |
你可以手动用 /deploy 斜杠命令调用,也可以让 Claude 自动判断——当你说”帮我部署一下”,它会自动匹配到 deploy 这个 Skill。
有人打了一个很好的比方:CLAUDE.md 像厨房里的常用调料,永远摆在台面上。Skills 像食谱书,需要做某道菜的时候才翻开。
一个好的 Skill 应该像写给初级工程师的操作手册——步骤清晰、工具明确、预期结果可验证。
Hooks:自动化的「卡口」
Hooks 是在特定事件发生时自动执行的脚本。我第一次用 Hooks 是因为一个很蠢的原因——Claude 写完代码从来不跑 Prettier,每次我 review 的时候格式都是乱的,烦得不行。
后来加了一个 PostToolUse 的 Hook,三行配置,问题就彻底解决了:
1 | { |
除了格式化,常见的 Hooks 还有:
PreToolUse:执行命令前检查有没有rm -rf这种危险操作SessionStart:会话启动时自动注入当前日期、环境变量Stop:Claude 完成回复后自动跑 lint
Hooks 和 Skills 的区别在于:Hooks 是硬规矩,不可商量;Skills 是操作建议,可以灵活调整。
Subagents:专业的「分身术」
Subagents 是 Claude Code 的子 Agent 机制。
主 Agent 可以派出多个子 Agent 去做不同的事,每个子 Agent 有独立的上下文窗口和工具权限。做完之后只把结果汇报回来,不会污染主 Agent 的上下文。
这跟 Anthropic Harness 论文里的「规划者-生成者-评估者」三角架构一脉相承。
常见用法:
- 派一个 Explore Agent 去读文档、搜代码
- 派一个 Test Agent 去跑测试
- 派一个 Review Agent 去检查代码质量
Plugins:打包分享的「插件包」
Plugins 是 2025 年底 Anthropic 推出的新机制,把 Skills、Hooks、Subagents、MCP Server 打包成一个可安装的插件。
1 | # 一条命令安装 |
这意味着你可以把自己的 Harness 配置分享给团队,也可以直接装别人打磨好的工作流。GitHub 上的 awesome-claude-code 项目收录了几百个插件,光是 everything-claude-code 这一个仓库就有 5 万多 star——可见社区的热情有多高。
实战:这套玩法到底有多大提升?
Anthropic 自己做了一个对比实验,用一句话提示词让 AI 生成一个复古游戏编辑器。
| 方案 | 耗时 | 花费 | 效果 |
|---|---|---|---|
| 裸跑(无 Harness) | 20 分钟 | $9 | 界面粗糙,核心功能不能用 |
| 完整 Harness | 6 小时 | $200 | 16 个功能模块,核心功能正常运行 |
裸跑的版本,游戏编辑器的「玩游戏」功能完全不能用——角色出现在屏幕上,但不响应任何输入。
Harness 版本不仅所有核心功能可用,还自动加上了 AI 辅助生成关卡、精灵动画系统、音效管理等高级功能。
后来他们用 Opus 4.6 简化了 Harness(去掉了 Sprint 机制),用一句话生成了一个浏览器端的音乐制作软件(DAW),花了 4 小时、$124。最终的应用有编曲视图、混音器、音轨控制,甚至内置了一个 AI Agent 可以通过对话来作曲。
说说我自己的上手路径
我知道看到这里信息量有点大。说说我自己是怎么一步步搭起来的,供你参考。
最开始我就是裸用 Claude Code,连 CLAUDE.md 都没写。结果就是前面说的,它经常乱改我不想动的文件。写好 CLAUDE.md 是我做的第一件事,大概花了 20 分钟,效果立刻就有。
用了一两周之后,我发现每次写博客都要重复输入一大段提示词——搜资料、定结构、写正文、生成封面。于是我把这套流程抽成了一个 Skill,现在输入 /writing-agent 加一个选题就搞定了。
后来又加了几个 Hooks。最有用的就是前面提到的 Prettier 自动格式化,还有一个是 SessionStart 时自动注入当前日期(写博客需要)。
至于 Subagents 和 Plugins,我现在用得不多。老实说,不是每个人都需要把 Harness 搞得很复杂。找到卡你脖子的两三个点,精准解决就够了。
最后说几句掏心窝的
说句可能得罪人的话:如果你花在调 Harness 上的时间比写代码还多,那你可能搞反了。
我在社区里见过不少人,CLAUDE.md 写了 2000 行,装了十几个插件,配了一堆 Hooks,结果 Claude 反而更懵了——规则太多,自相矛盾,它不知道该听哪个。
Harness 的精髓不是把 Claude 武装到牙齿,而是找到那两三个真正卡你脖子的点,精准解决。
对我来说,CLAUDE.md + 两三个常用 Skill + 一个格式化 Hook,就已经覆盖了 80% 的场景。剩下的 20%?模型自己在进步,Opus 4.6 已经不需要像 4.5 那样做 Sprint 分解了——很多之前需要 Harness 补救的问题,模型升级后就自动消失了。
这也是 Anthropic 自己在博客里说的:每一个 Harness 组件,本质上都是在赌模型做不到某件事。这个赌注随时可能过期。
所以我的建议是:轻装上阵,按需添加,别一开始就搞顶配。
你在用 Claude Code 吗?踩过什么坑,或者有什么特别好用的配置?评论区聊聊,我想看看大家都是怎么玩的。