Codex 不写 Spec 了,改玩 Skills:AI 编程的产品方法论正在换代
大家好,我是飞飞。
最近在用 Codex 和 Claude Code 写代码的时候,我发现一个明显的变化:Spec 这个词出现的频率越来越低了,取而代之的是一个新词 —— Skills。
不是那种简历上写的”熟练掌握 Java”的 skills。是一种全新的 AI Agent 能力封装方式。
这个变化不是小打小闹。它背后是整个 AI 编程产品方法论的一次换代。
Spec Driven Development:曾经的”正确答案”
先说说 Spec 是怎么火起来的。
2025 年底到 2026 年初,AI 编程圈最热的概念是 Spec Driven Development(SDD)。核心思路很简单:你先写一份详细的需求规格说明书,把要做什么、怎么做、边界条件都写清楚,然后把这份 spec 喂给 AI agent,让它照着执行。
听起来很靠谱对吧?实际上确实管用。
Anthropic 用这个方法让 Claude 从零开始用 Rust 写了一个 C 编译器。Vercel 用它造了一个 TypeScript 版的 bash 模拟器。GitHub 甚至专门做了一个 spec-kit 工具来标准化这个流程。
SDD 解决了 vibe coding 的核心痛点:AI 瞎猜需求。有了 spec,AI 就有了明确的执行依据。
但用过一段时间之后,问题开始浮出水面。
Spec 的三个硬伤
第一,写 spec 本身就很累。
一个好的 spec 需要覆盖功能描述、边界条件、测试用例、架构约束。写完一份完整的 spec,可能比直接写代码还费时间。有人在 Reddit 上吐槽:”我花了两小时写 spec,AI 花了三分钟生成代码,然后我又花了一小时修 AI 生成的 bug。”
第二,spec 是一次性的。
你为项目 A 写的 spec,换到项目 B 基本没法复用。每次开新项目、做新需求,都得从头来。那些关于”怎么写测试”、”怎么做 code review”、”怎么部署”的流程,每次都要重新描述一遍。
第三,spec 消耗大量 token。
一份详细的 spec 加上相关的测试文件、架构图,轻松就是几千行 markdown。全部塞进上下文窗口,既贵又浪费。大部分 spec 内容在执行的某个阶段根本用不到,但你不得不带着它。
于是,一种新的方案开始冒头。
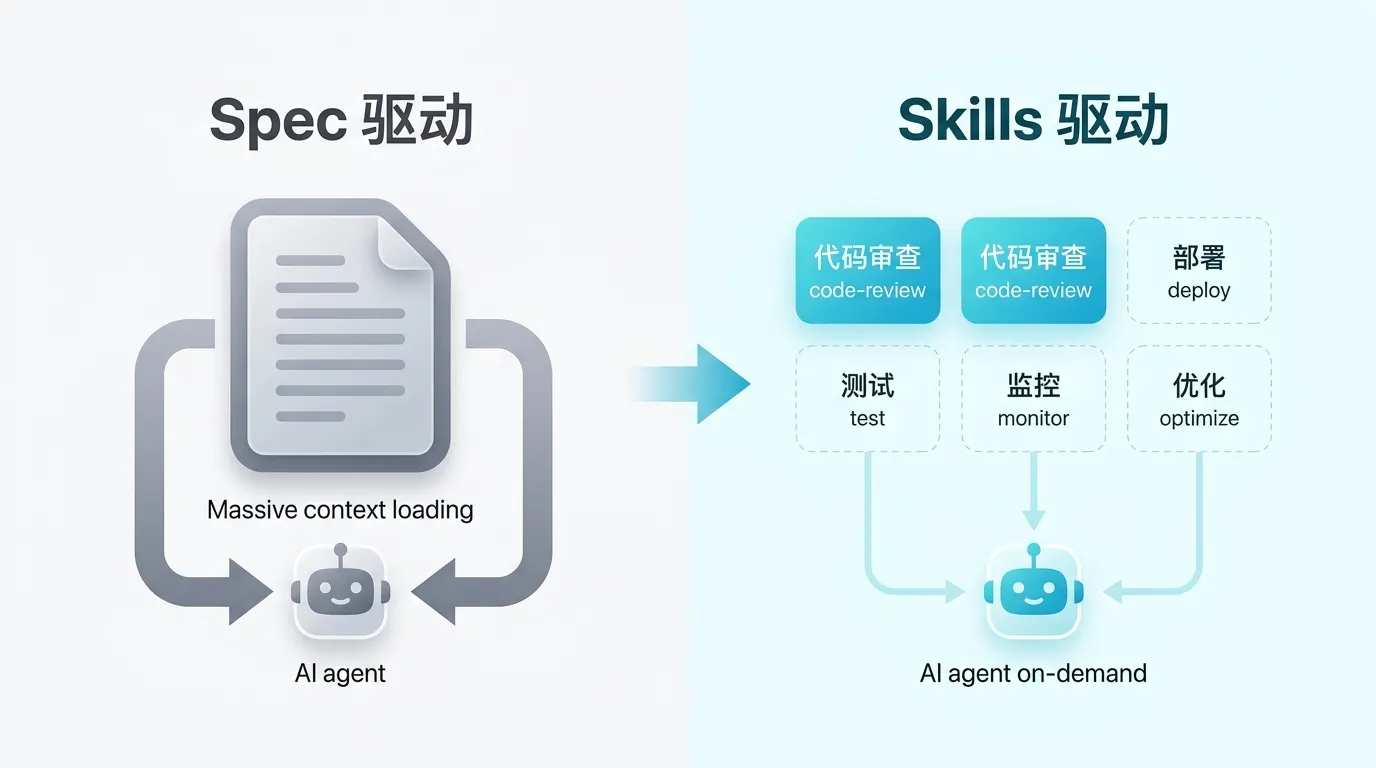
Skills:从”一次性文档”到”可复用能力模块”
2026 年初,Codex 团队做了一个关键决策:全面拥抱 Skills 体系。
Skills 是什么?简单说,就是把 AI agent 的工作流封装成一个个独立的”技能包”。每个技能包是一个文件夹,核心是一个 SKILL.md 文件,里面写着:这个技能叫什么、什么时候该用、具体怎么执行。
比如,你可以有一个 code-review 技能,一个 deploy 技能,一个 write-test 技能。AI agent 遇到对应的任务时,自动加载对应的技能,执行完就释放。
和 spec 最大的区别在哪?
Spec 是面向”项目”的,Skills 是面向”任务”的。
Spec 说的是”这个项目要做成什么样”。Skills 说的是”遇到这类任务该怎么干”。
一个是蓝图,一个是工具箱。
Codex 的 Skills 架构:渐进式上下文加载
Codex 在 Skills 的实现上有一个很精妙的设计:渐进式上下文加载(Progressive Disclosure)。
传统的 spec 方式是把所有内容一次性塞进上下文窗口。Skills 不一样。Codex 启动时,只加载每个技能的元数据 —— 名字、描述、文件路径。只有当它判断当前任务需要某个技能时,才会去读取完整的 SKILL.md 内容。
这意味着你可以装 50 个技能,但上下文窗口里可能只占用几百个 token 的元数据。需要的时候按需加载,用完就释放。
这个设计带来了几个好处:
- Token 消耗大幅降低。 不用每次都带着完整的 spec 跑。
- 技能可以叠加,不冲突。 50 个技能各管各的,互不干扰。
- 新技能即插即用。 丢一个文件夹进去,agent 自动发现。
Codex 还支持 6 层技能作用域:当前目录、父目录、仓库根目录、用户级、管理员级、系统级。团队可以在仓库里放共享技能,个人可以在自己目录下放私人技能,互不干扰。
更大的事:Skills 成了跨平台开放标准
如果 Skills 只是 Codex 一家的玩法,那顶多是个产品特性。但事情比这大得多。
Agent Skills 已经成为了一个跨平台的开放标准,规范发布在 agentskills.io。这个标准最早由 Anthropic 为 Claude Code 设计,后来被 OpenAI Codex 采纳,现在已经有超过 30 个 AI 编程工具支持它。
Claude Code、Codex、Gemini CLI、Cursor、GitHub Copilot、Windsurf、JetBrains Junie…… 用的都是同一套 SKILL.md 格式。
这意味着什么?你写一个技能,到处都能用。
在 Claude Code 里写了一个 deploy 技能,直接软链接到 Codex 的技能目录,一样能跑。社区里已经有人做了跨平台技能同步工具,一键把技能部署到所有支持的 agent 上。
截至目前,社区里已经有 2636 个公开的 SKILL.md 技能文件,这个数字每个季度都在翻倍。OpenAI 自己也开源了官方技能仓库。
从工具到生态:Skills + MCP + Plugins
Skills 不是孤立存在的。Codex 把它放在了一个更大的框架里:
- Skills 定义可复用的工作流
- MCP(Model Context Protocol) 连接外部工具和系统
- Plugins 是 Skills 的分发单元,方便安装和共享
- Subagents 把任务委派给专门的子 agent 执行
这四个东西组合在一起,Codex 从一个”写代码的工具”变成了一个”agent 工作流系统”。
一个 blog 有篇文章说得好:到 2026 年 3 月,Codex 最好的理解方式不再是”又一个 AI 编程工具”,而是”一个真正的跨平台 agent 工作流系统”。
为什么这个转变值得关注
回过头来看,从 Spec 到 Skills 的转变,本质上是 AI 编程从”文档驱动”走向”能力驱动”。
Spec 的思路是:先把所有事情想清楚,写下来,然后一次性执行。这是瀑布模型的 AI 版本。Skills 的思路完全不同:把经验封装成可复用的模块,遇到什么问题就调用什么能力。更像微服务的理念。
我自己的体会是,自从开始把日常工作流封装成 skills,效率提升非常明显。比如我给博客写了一套内容创作的 skills 流水线 —— 调研、写作、润色、配图四个技能串起来,一个命令就能从选题跑到成品。这套东西我在 Claude Code 上写的,理论上搬到 Codex 也能直接用,因为 SKILL.md 格式是通用的。
所以我的建议是:别再把时间花在写一次性 spec 上了。花同样的时间写一个技能,它可以在所有项目里跟着你。你给 AI agent 攒的技能越多,它能干的活就越多,边际成本越来越低。
另外,写技能的时候记得别绑死在一个平台上。今天用 Claude Code,明天可能切 Codex,你的技能不应该白费。
还有一点:习惯”编排”的思维。单个技能解决单个问题,多个技能串起来才能完成复杂任务。以后越来越多的工作不是”写代码”,而是”拆任务、选技能、编排流程”。
有人说,写代码的时代结束了,写 prompt 的时代开始了。我觉得不完全对。
更准确地说,写”一次性 prompt”的时代快结束了。写”可复用技能”的时代,刚刚开始。
你在用 Agent Skills 了吗?有没有什么好用的技能推荐?欢迎在评论区分享。