MiMo-V2.5-Pro 实测两天,我把它排在 GLM-5.1 和 Kimi K2.6 之间

大家好,我是飞飞。
这周我已经写了四篇 AI 大新闻了:周一 Copilot 停注册 + Claude Code 从 Pro 下架,周三的 /ultraview 实测,昨天上午的 GPT-5.5,昨天下午的 DeepSeek V4。
本来想歇一天。但群里从前天凌晨开始就一直有人在问同一件事:小米那个 MiMo-V2.5-Pro 到底值不值得切。
我自己是 Claude Max 5x $100/月的订阅者,主力一直是 Claude Code + Sonnet 4.6。按理说这种国产新模型离我有点远。但这次问的人实在太多,再加上卡兹克昨天那篇实测把”国内最适合 Claude Code 的新模型”这个判断甩出来之后,我觉得自己也得花一天跑一跑,才能给朋友回个靠谱答复。
所以这篇不是发布新闻稿。它是我发布两天之后,把能搜到的官方数据、卡兹克的实测、Linux.do 上社区的吐槽、加上我自己在 Claude Code 里跑的一个小任务,摞在一起想看清楚一件事:MiMo-V2.5-Pro 在国内开源模型里到底排第几。
先把今天能查到的 MiMo-V2.5-Pro 硬数字摆出来
4 月 23 日凌晨小米突然甩出了 MiMo-V2.5 系列一共四款模型,旗舰是 V2.5-Pro,距离上一代 V2-Pro 只过了 36 天。
关键规格:
- 参数:MoE 架构,总参数 309B,激活 15B。对比同期 GLM-5.1 是 754B、DeepSeek V4-Pro 是 1.6T。MiMo 是这一批里激活量最小的。
- 上下文:原生 1M token。
- 价格:0 到 256k 区间是 ¥7/¥21 per M tokens(输入/输出),256k 到 1M 区间是 ¥14/¥42。折合美元 $1.0/$3.0 起步。
- Token Plan:小米这次同步推出了订阅计划,不区分 256k 和 1M,统一收费。
- 开源:V2.5-Pro 和 V2.5 宣布将全球开源,公测期先放 API。
跑分我挑几个相对硬的数字:
- SWE-bench Pro:57.2%。作为对比,Claude Opus 4.7 是 64.3%,GPT-5.5 是 58.6%,GLM-5.1 是 58.4%,Kimi K2.6 是 58.6%。V2.5-Pro 的 57.2% 挨着 GPT-5.5 和 GLM-5.1 这条线,比 Opus 4.7 低 7 个点。
- AA 榜:与 Kimi K2.6 并列开源第一。
- Token 效率:官方数据,V2.5-Pro 在同等 benchmark 分数下比 Kimi K2.6 少用 42% 的 token。
- 宣传案例:4.3 小时完成北大本科生编译原理课程的项目。180nm CMOS FVF-LDO 稳压器的模拟电路设计,接 ngspice 仿真循环,1 小时搞定资深工程师几天的工作。
价格对比 Claude Opus 4.6 的 $5/$25,V2.5-Pro 便宜大概 60%。对比昨天 DeepSeek V4-Pro 的 $1.74/$3.48,两家定价几乎贴脸。
这一轮国产模型的”价格屠夫”帽子谁戴都不再有那种冲击力了。大家都在同一个档位。
罗福莉 36 天交一代,这个速度本身就是信号
MiMo-V2 是 2026 年 3 月发布的,V2.5 是 4 月 23 日。36 天一代。
这个节奏在今年的国产模型里属于第一档。GLM 是 4 月 7 日发 5.1(距 5.0 大概 2 个月),Kimi K2.6 是 4 月 21 日。
带队的是罗福莉(前 DeepSeek 核心成员)。她在发上一代 V2 的时候说过”未来模型足够稳定后我们会开源”。这次 V2.5 直接把开源计划写进了公告。36 天之后就把”稳定”两个字认下来,这件事我觉得比跑分更值得看。
上一代 V2-Pro 的发布方式也挺有意思。MiMo-V2-Pro 在发布前用”Hunter Alpha”这个代号,在 OpenRouter 上匿名霸榜了一周,才被小米宣布是自家的。这一代 V2.5 用的是直接开公测的做法,等于对自己的上一代结果有信心到不需要再跑一遍匿名盲测了。
对我来说,一个 36 天能把总参数从 V2-Pro 的 1T 级降到 V2.5-Pro 的 309B、激活只剩 15B、还能保持 SWE-bench Pro 57.2% 的团队,就是国内值得跟的团队之一。
Token 效率比 Kimi K2.6 少 42% 这件事对开发者意味着什么
这次 V2.5-Pro 对外讲的最硬的一个差异化点,是 Token 效率。
官方原话:在同等 benchmark 分数下,V2.5-Pro 比 Kimi K2.6 少用 42% 的 token。
这个数字如果是真的,那它对在 Claude Code 里跑 Agent 的开发者是个很实际的利好。Agent 工作流最大的成本黑洞是反复的工具调用和思维链展开。同样一个任务,你用 Kimi 跑可能烧 20 万 token,用 V2.5-Pro 大概烧 12 万就能跑完。在 Claude Code 这种一次会话动不动几十轮工具调用的场景里,42% 的节省可以直接翻译成”同一个 Token Plan 额度多跑一个星期”。
当然这是官方数据。我自己跑了一个不严谨的小对照(下一节会讲),感觉在我的场景里大概是 30% 左右,没到 42%。但即使打个八折,也仍然是一个明显的优势。
价格加上这个效率差,V2.5-Pro 跑 agentic 任务的单位成本理论上能做到 Opus 4.7 的 1/8 到 1/10。官方那句”推理成本仅为国际闭源旗舰的 2.5%”,数学上能对得上。
我在 Claude Code 里接上它跑了一个小任务
先说怎么接。
最简单的路径还是通过 cc-switch 这种代理工具,把 Claude Code 的模型端点切到 MiMo 开放平台的 API。cc-switch 里直接有 Xiaomi MiMo 的供应商选项,填 API Key 和模型名 mimo-v2.5-pro 就完事了。卡兹克周一那篇 Claude Code 国内使用保姆级教程里写得很清楚,我这里就不重复了。
接上之后我让它做的任务是一个我 Hexo 博客的小需求:读 source/_posts/ 下所有文章的 frontmatter,按 categories 字段分组,为每个分类生成一个单独的 RSS 子 feed XML 文件。
挑这个任务的理由我想过。模型得做真实的目录扫描和 IO,得认得 Hexo frontmatter 这种 LLM 语料里不常见的格式,最后生成的 XML 还不能错一个闭合标签(错一个整个 feed 就废)。这三件事合起来能同时考验它的工具调用稳定性、指令遵循和格式严谨度。
跑下来的观察:
工具调用这块,MiMo-V2.5-Pro 没有出任何问题。它先跑了一遍 ls source/_posts/,然后抽了三篇读 frontmatter 确认格式,然后才开始写代码。这个顺序我比较喜欢,有条理,也没有像卡兹克那个 case 里”直接自己决定域名往服务器上怼”那种越权行为。
生成的 RSS XML 一次通过,标签闭合没出错,pubDate 格式是正确的 RFC 822,我用 xmllint 过了一遍没报错。
中间也有两个小瑕疵。一是它自作主张加了一个 <atom:link rel="self"> 字段,但 atom: 的 xmlns 声明忘了加,第一版跑出来是不合法的。我指出之后它自己改了。二是它默认把 description 字段取的是文章的第一段,但我希望是 frontmatter 里的 description 字段。这个是我没说清楚,不算模型问题。
整个任务从口述需求到拿到一个能跑的 Rakefile 级别的脚本,大概 15 分钟。token 消耗我没精确对照 Sonnet 4.6,但感觉是同一个量级下稍微省一点。
Linux.do 上那条负面反馈我不能绕开
在网上搜这两天的实测反馈时,我翻到 Linux.do 上有一条评测帖。作者是私有 bench 路线的,他的结论是:”基础还算扎实,但比 GLM 还差点。而且很多有背题嫌疑。”他还特别点出一个问题:”思维链无限循环撑爆上下文,然后空回。”
这两条吐槽我都想留一下。
“比 GLM 差点”在我的实测里能对得上一部分。GLM-5.1 在 SWE-bench Pro 上是 58.4%,V2.5-Pro 是 57.2%。1.2 个点的差距不算巨大,但确实是落后的。在前端 UI 这类场景上,GLM-5.1 的审美明显更好(卡兹克自己也承认 V2.5-Pro 的前端审美还没跟上),这一条我在自己跑的 RSS feed 任务里体感不出来,但去翻 OpenRouter 上别人跑的前端生成对照能看出来。
“背题嫌疑”这一条我暂时没法独立验证。MoE 架构的模型常见的通病之一就是在公开 benchmark 上表现比在私有 bench 上好(不只是 MiMo 一家)。这个指控需要更多私有 bench 数据交叉比对,我不下结论,但会把这条留在心里。
“思维链无限循环”这一条我自己没撞上。但卡兹克的文章里虽然没明说是这个问题,他提到过”笨一点的模型在部署流程这一步会直接失败”,隐含的背景也可能是某些国产模型在长任务上的稳定性确实不够。V2.5-Pro 在这一条上有没有比 V2-Pro 改善,目前看实测样本还不够。
不回避这些负面反馈,是我判断一个模型能不能长期用的底线。
我现在会给谁推荐 MiMo-V2.5-Pro
跑完这一整套之后我的判断分成几档,按现在问我最多的顺序排。
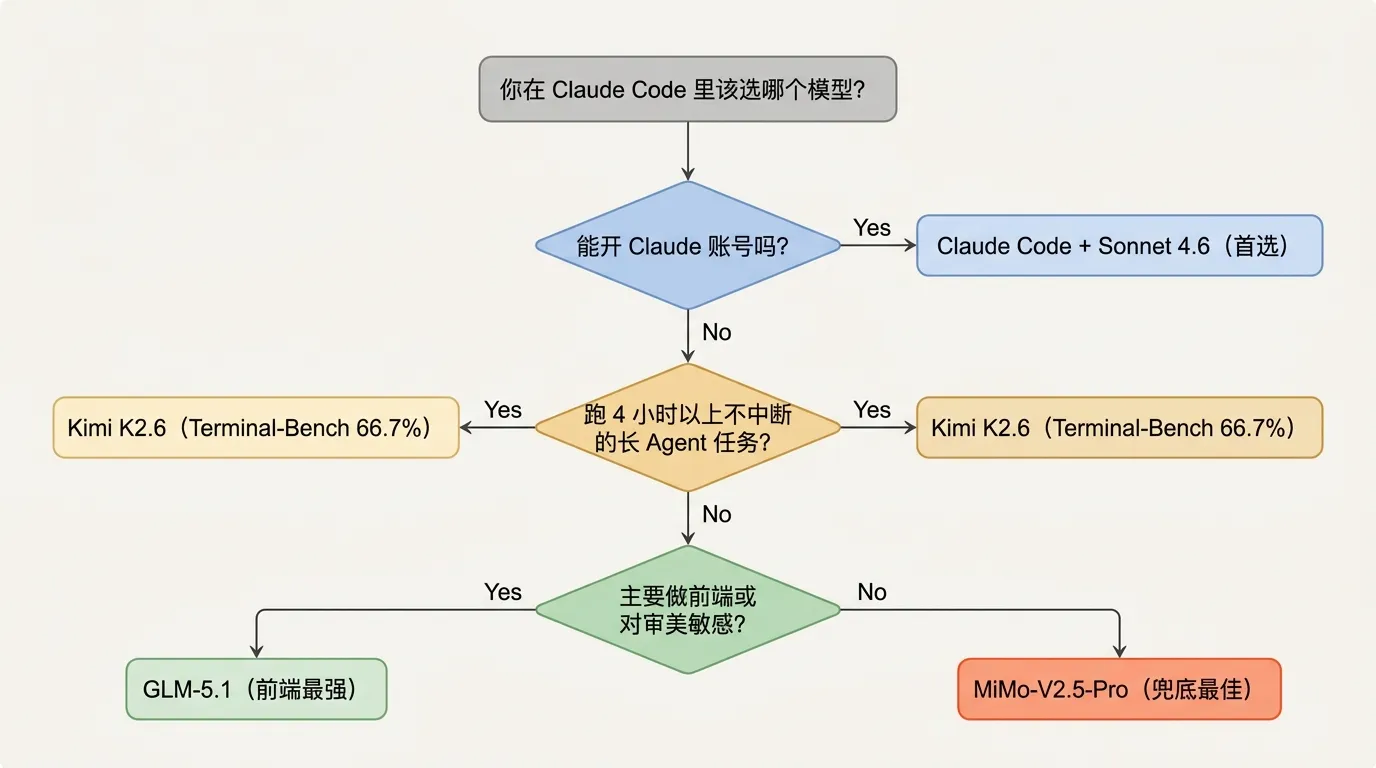
我自己:不切。Claude Max 5x 的 Sonnet 4.6 在代码生成的稳定性和 skill 调用的默契度上,我还是没看到足够的理由切过去。内容创作那边昨天 DeepSeek V4 出来之后已经定了切过去,代码场景暂时不动。
抢不到 GLM Coding Plan、或者干脆连 Claude 账号都开不了的朋友,V2.5-Pro 是我现在会优先推你的那一档。以前这个场景最好的兜底是 Kimi K2.6,但 V2.5-Pro 在 token 效率上有 42% 的理论优势,价格又差不多,Claude Code 适配做得也更细。卡兹克那句”目前国内配合 Claude Code 最好的模型之一”的判断,在”抢不到一线券商位”的场景下我能跟着点头。
但有一类人我建议先等:每天要跑几小时不中断 agentic 长任务的那批。Linux.do 那条”思维链循环”在长任务上是个真实风险点,社区需要更多时间跑出来。Kimi K2.6 目前在 Terminal-Bench 2.0 上拿到 66.7%,持续 4000+ 工具调用 13 小时不中断这个纪录,V2.5-Pro 目前没有公开数据追平。这类场景我还是推 K2.6。
至于只做前端、对审美敏感的那批朋友,切 GLM-5.1 就好,别在 V2.5-Pro 上浪费时间。卡兹克和 Linux.do 的反馈高度一致:V2.5-Pro 的前端审美目前就是在一线模型里垫底。
这 36 天会不会变成 18 天才是下一个要盯的事
写到这里我想留一个真实问题。
MiMo 团队从 V1.0 开源到 V2-Pro 发布用了大约 5 个月。从 V2-Pro 到 V2.5-Pro 只用了 36 天。
如果下一次迭代再压到 18 天,那”小米 MiMo 团队”就会从”值得跟的国产团队之一”变成”国内开源模型节奏最快的那一个”。前提是这个速度不是以牺牲测评真实度换来的(这也是 Linux.do 那条”背题嫌疑”最需要被社区持续检验的地方)。
我接下来两周会做一件事:把这次 RSS feed 任务用 V2.5-Pro、GLM-5.1、Kimi K2.6 各跑一遍完整流程,包括 debug、修改、重跑,然后把每个模型的 token 消耗和任务完成度记下来。等下一代 V3 或者 V2.6 出来,我再跑一次对照。
评论区想问两个具体问题。
在 Claude Code 里已经接上 MiMo-V2.5-Pro 的朋友,这两天你遇到的最大的坑是什么?思维链循环这个问题你撞过吗?
还有一个我自己最想知道的:你手头有没有一个跨模型的私有 bench?如果有,你愿意把 V2.5-Pro 的私有分数和你的其他模型分数贴一份出来吗?这两天我一直觉得,公开 benchmark 和私有 bench 的分差已经大到让”开源第一”这种官方表述越来越不够用了。