智谱把模型干到了 400 tokens/s,国产开始卷速度了
哈喽,我是飞飞。
5/22 早上我刷到 400 这个数字,第一反应是看错了
5 月 22 号早上,我刷到智谱发了个新东西叫 GLM-5.1 高速版,输出速度 400 tokens/s。
第一眼没什么反应。国产模型这两年发布会太多了,看到这种新闻已经麻木。但隔了 30 秒我意识到 400 这个数字不对劲。
普通 GLM-5.1 大概 44 tokens/s,Claude Opus 4.6 标准模式 44,DeepSeek 官方 API 30 到 35。Gemini 3 Flash 算业界比较快的一档 121。最快的 Mercury C 是 633,但用的是 diffusion 架构,能力不在第一档。
智谱直接干到 400,而且是旗舰能力的旗舰,没有为了快阉割掉能力。
说白了,全球大模型 API 的速度天花板被顶高了一截。
上手摸了一遍企业 API,眼睛追不上吐字的速度
我立刻申请了企业 API 权限上手测了一下。
上来先扔一段 React 组件重构,把一个 800 行的列表组件改写成 useMemo + virtualized 版本。我盯着输出窗口,代码像字幕一样从上往下飞过去。下意识想用 Cmd+F 去定位变量名,手还没碰到键盘,整段代码已经吐完了。
换下一个,丢一份 35 页 PDF 行业报告进去让它总结核心论点。同样的任务我用 Claude Code 跑过几次,每次要等 40 到 60 秒。这次数到 6 秒,结果出来了。
再试 Agent 链。让它先抓一个 GitHub repo 的 README,再读源码目录,再生成一段中文技术解读。三个动作连着跑下来不到 15 秒。
测试结束时我有种很奇怪的感觉。模型还在那儿一边思考一边吐字,但我的眼睛已经追不上它的速度了。
副作用也有一个:太快导致来不及打断。PDF 总结那一轮里,它有一段方向跑偏了,但等我意识到的时候它已经吐完结论。Claude Code 那种「慢慢吐字给你时间叫停」的节奏,在这儿不存在。
把 400 翻译一下:是人类阅读极限的 80 倍
人类正常阅读速度大概是 3 到 5 个 token 每秒。对,就这么慢。觉得自己看文章很快,其实绝大多数时候是在跳读。认真看每一个字,3 到 5 个 token 就是上限。
400 tokens/s 是这个的 80 倍。AI 在 1 秒内吐出来的东西,你需要花 80 秒才能读完。
落到具体场景。Cursor 或 Claude Code 让你生成 2000 token 代码,标准模型要 50 秒,够你去厨房接杯水回来。换成 400 tokens/s 是 5 秒,刚把手从键盘上挪开,代码已经全部出来。
50 秒那种叫「等 AI」:下命令然后等,等的时候打开微信刷两条朋友圈,结果出来再回头检查。
5 秒那种叫「跟着 AI」:你的眼睛、思维和模型几乎同步,看着代码流出来,发现哪里写偏了立刻按 Esc 改方向。
这种差距大到「快了一点」根本描述不了,整个交互范式被换了一套。
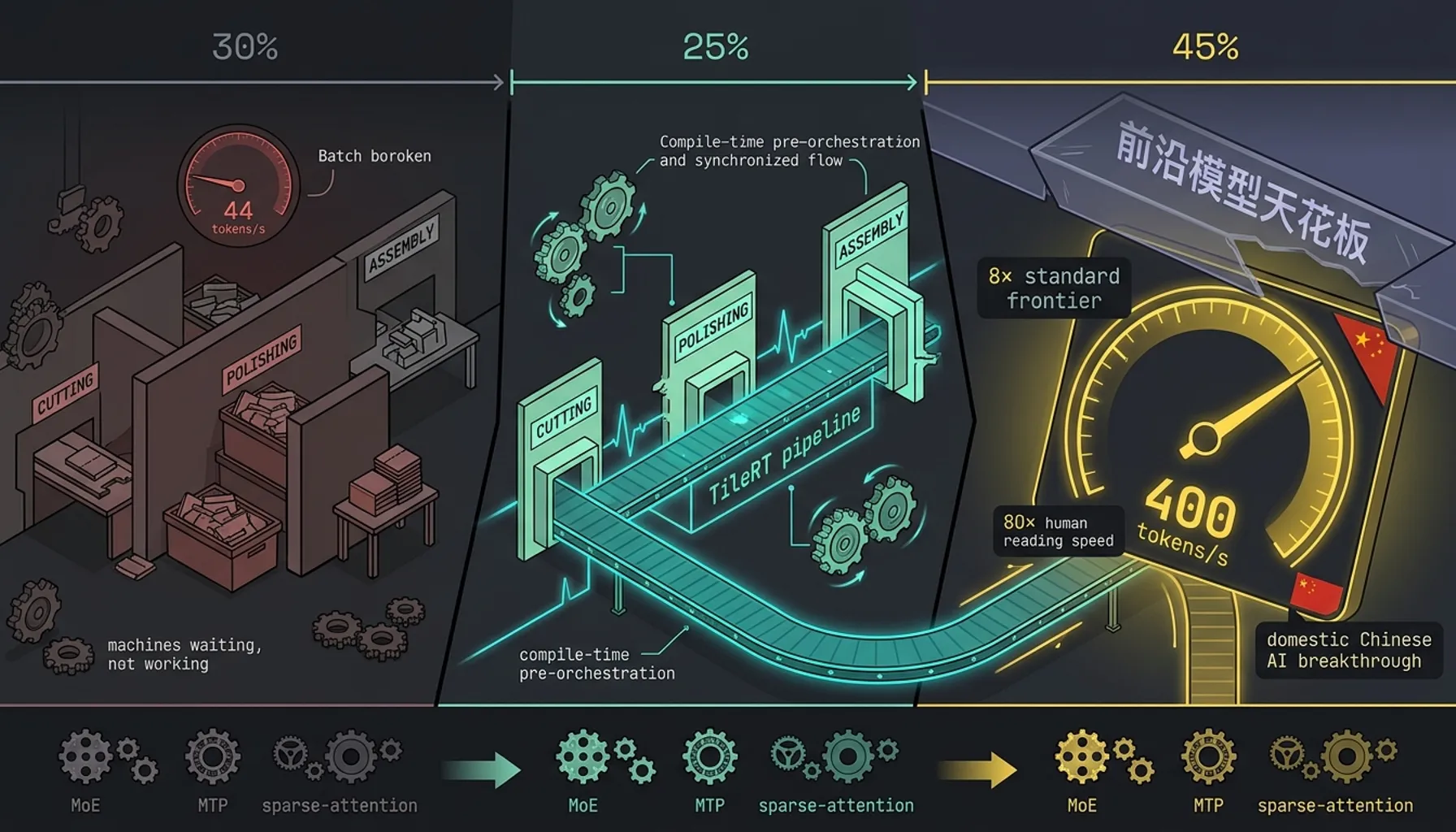
TileRT 把推理工厂从批处理改造成连续流水线
理论上推理速度上限由硬件决定。一台 8 卡 H200 服务器按理论带宽算 decode 上限差不多 1000 tokens/s。但主流推理框架跑出来常常只有几十 tokens/s,中间差了一个数量级。
TileRT 团队博客里有个比喻特别好。想象一个工厂,里面分好几个工位,一个切割,一个打磨,一个装配。
主流推理框架是这么干活的:工头喊「开工」,第一个工位做完整批,半成品送进仓库。工头再喊一声,第二个工位从仓库把半成品搬出来接着做。
如果这批量很大,每个工位忙几十甚至几百毫秒,进出仓库的几微秒可以忽略。但实时交互场景里每次只生成一个 token,工位处理时间被压缩到几微秒。工件加工 2 微秒,搬运用了 5 到 10 微秒。超过一半的时间机器都在等下一个工位「准备好」,不是在干活。
GPU 利用率看着挺高,算力理论上也够,但 token 就是吐不快。卡在工位与工位之间的那堵墙上。
TileRT 干的事儿就是把整个工厂从「批处理车间」改造成「连续流水线」。
不再等一整批做完再送仓库,而是一件一件直接传给下一个工位。工头只在最开始喊一次「开工」,之后所有调度、同步、传递都在车间内部完成,再也不停机。
更狠的是这条流水线在编译期就预先编排好了,运行时根本不需要即时调度。把流水线塞到 GPU 里让它一直跑。工位之间那堵墙被拆掉了。
GLM-5.1 模型架构本身就奔着配合推理引擎做的
光有流水线还不够,得让上面跑的东西也对流水线友好。
先说 MoE 稀疏激活。744B 总参数里每个 token 只激活 40B。工厂虽大,订单进来时只调用相关那几个工位,不用整个仓库都翻。
再说多 token 预测,简称 MTP。传统模型每生成一个 token 都要把整个模型跑一遍。GLM-5 训了一手,让模型一次预测接下来 2 到 3 个 token,再由主模型快速校验。实际平均每次稳定吐出 2.76 个,比 DeepSeek-V3.2 的 2.55 还高一点。
还有稀疏注意力。长上下文下传统注意力复杂度跟长度的平方成正比。稀疏注意力让模型自己判断哪些 token 重要,只对重要的做计算,砍掉 1.5 到 2 倍算力开销。
省下来的算力,正好被流水线拿去掩盖数据搬运和卡间通信的时间。模型和引擎互相给对方留头部空间。400 这个数字是这三层加上 TileRT 的执行模型重构搭在一起才出来的。
国产大模型,开始卷别人没走过的方向
让我头皮发麻的不是 400 这个数字本身,是国产大模型开始卷速度了。
目前 API 速度梯队大致这样:极速档超过 200 tokens/s,GLM-5.1 高速版之前只有 Mercury C 一家达到 633,但是 diffusion 架构,能力不在第一线。快速档 100 到 200 tokens/s,Gemini 3 Flash 121,Claude Fast Mode 100 到 112,GPT-5.1 95 到 120,DeepSeek V4 Pro 在第三方推理服务商上能跑到 170。标准档 40 到 100 tokens/s,绝大多数前沿模型都在这里。
智谱直接干到 400,把原天花板顶到新位置,而且是旗舰能力的旗舰。更巧的是 DeepSeek 同一天宣布把之前 75% 的促销折扣永久化,API 价格变 1/4。一个卷速度,一个卷价格。
实话讲,中国的大模型厂商已经从「我们也能做到」开始往别人没去过的方向走。前两年是在追,每发一个模型第一句话都是「在某某 benchmark 上超过了某某」,潜台词是「我们也有了」。今年不一样:DeepSeek 把推理价格打下来一个数量级,是别人没敢干的。智谱这次直接重写推理执行模型把速度干到 400,也是别人没去做的方向。
国际厂商怎么做的:Anthropic Fast Mode 是同一个模型调推理配置,2.5 倍速度换 6 倍价格。Google 的 Flash-Pro 分级是直接训不同大小的模型覆盖速度和能力的光谱。Fireworks 这类第三方推理服务商是在现有框架上做单点优化。
智谱走的是第四条路:根上动手术,把整个推理执行模型从批处理改成连续流水线。最深、最难、回报也最大。
Claude Code 用了快一年,慢一直是我心里那点别扭
Claude Code 我用了快一年,依赖到不可逆的程度。但有件事一直别扭:写一个复杂 prompt 之后等 30 到 50 秒看结果,几乎每天都在发生。
这个等待时间挺尴尬。说短不短,长到我会本能切到飞书或推特刷两眼。说长不长,等回来重拾上下文比直接等还累。切走再切回来思路断了,这 prompt 等于白写。
我试过 Claude 的 Fast Mode 和几个第三方推理服务,确实快一些但能力损失明显,复杂 Agent 链跟不上。
GLM-5.1 高速版让我第一次意识到,慢这件事可以被解决。能力跟 Claude Code 完全一样还远着呢,但「快」第一次被推到「快到需要重新适应交互节奏」的程度,跟「快了一点点」完全两个东西。
就像十年前第一次从机械硬盘换到 SSD:开机时间从 90 秒压到 10 秒,看起来只是数字变化,但整个 workflow 节奏被重写了一遍。这次给我的体感几乎一样。
智谱 SLA 数据和 DeepSeek 是否反击,这两件事我会盯着
但也得说几句心里的别扭。
400 tokens/s 这个数字目前还没被 Artificial Analysis 这种独立第三方测过。智谱自己也承认需要更多条件下的持续验证。我看到的更多是一个声明加少量企业客户实测,普通开发者还摸不着。
9 倍速度提升,单位 token 成本是不是也跟着便宜,定价怎么算,目前没看到具体数字。Anthropic Fast Mode 那种 2.5 倍速度换 6 倍价格的玩法市场会买账。但 400 tokens/s 如果价格跟着 9 倍 10 倍往上走,那它就是一个高端定制服务,不是普惠工具。
这些都还不清楚。但速度作为新的竞争维度被打开了。
我要盯两件事。一是智谱的 SLA 数据和正式定价区间什么时候出来,能不能从企业内测扩到通用开发者。二是 DeepSeek 会不会接着卷速度反过来回应。它过去一年都是「价格 + 能力」两条腿走,速度这条腿如果也迈出来,国产推理这块就真彻底拉开。
之前搭流水线只想着能不能跑通,没想过跑通之后在烧什么时间。GLM-5.1 高速版让我意识到,「等待时间」本身就是一种被忽略的成本。
智能 × 速度,是未来三五年 AI 行业的新战场。第一记发令枪,恰好被一家中国公司打响。