Qwen3.7-Max 冲到 Code Arena 全球第 2,1M context 跑 35 小时不掉线
哈喽,我是飞飞。
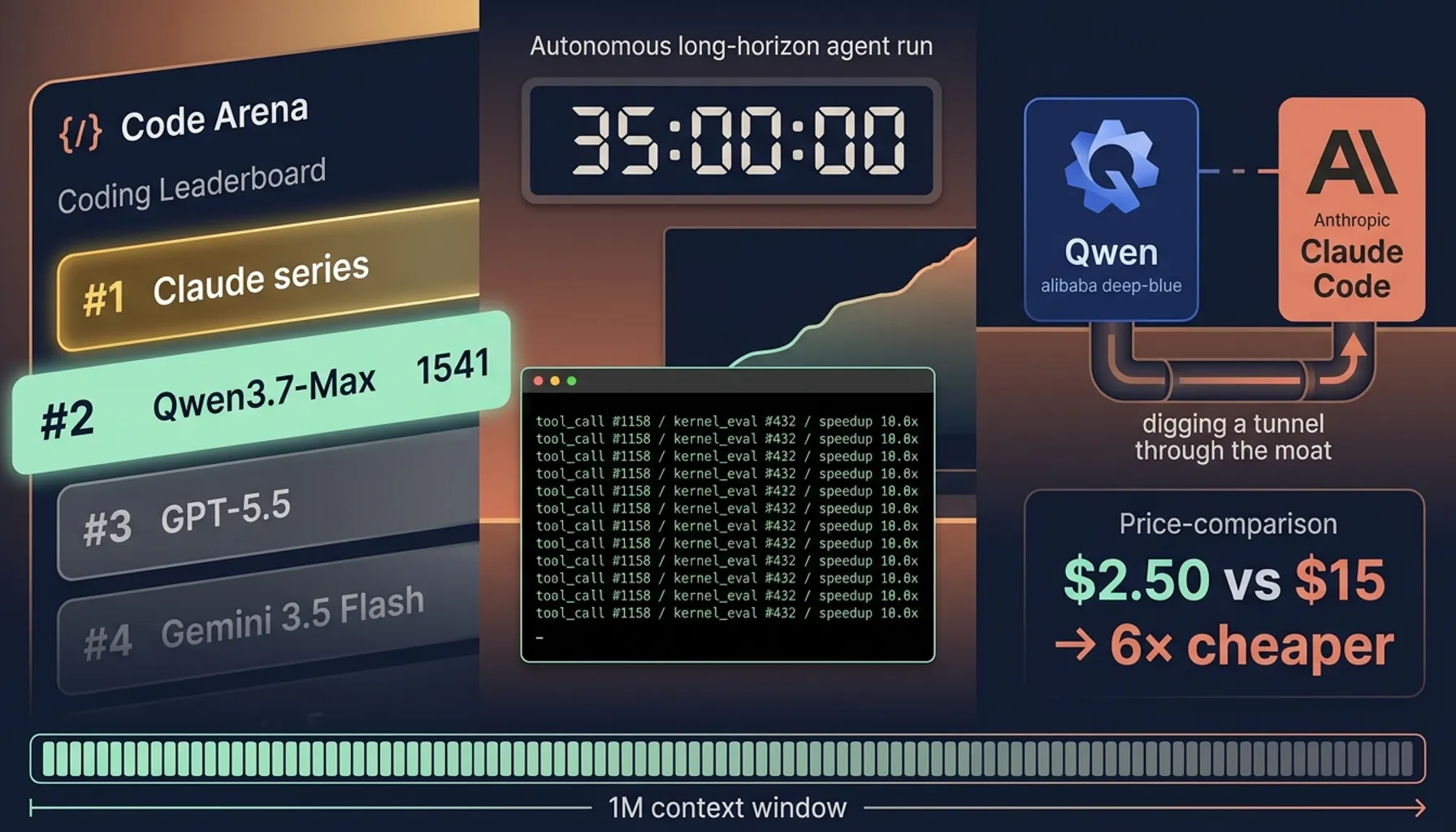
上周阿里 Qwen 团队 push 出了 Qwen3.7-Max,编程能力直接冲到 Code Arena 全球第 2,前面只剩 Claude 系列。这个分数本身已经够上新闻头条,但真正让我盯着 blog 看了半天的,是后面那串数据。连续 35 小时自主运行、1158 次 tool calls 不掉上下文、在阿里自家从未训过的芯片上拿到 10 倍加速。加上价格比 Claude Opus 4.7 便宜 6 倍这一刀,国内开发者第一次有了能跟客户报价的长链路 agent 模型。
上周阿里 Qwen 团队发的那篇 blog 我盯着屏幕坐了一会儿
5 月 20 号阿里 Qwen 团队推出 Qwen3.7-Max,blog 标题就一句话:「The Agent Frontier」。我点进去先扫了一遍 benchmark,看到 Code Arena 1541 排第 2 的时候说真的没怎么动心。国产模型冲榜这两年看得太多了,今天第 8、明天第 5、后天又掉回来,已经审美疲劳。
让我坐住的是后面那块内容。35 小时连续自主跑,1158 次 tool calls 不掉链,价格比 Claude Opus 4.7 便宜 6 倍。我第一反应是去翻知乎和即刻,国内的讨论度跟英文圈完全不成正比。AIbase 和 36 氪发了快讯但深度复盘几乎没有,Reddit 那边已经一堆 hands-on 评测,老外讨论得比中文圈热闹得多。
这事我得自己写一篇捋一下。
1541 分这个位置,阿里以前没在编程榜爬到过
Code Arena 是 LMArena 体系下的编程子榜,跟 Text Arena 一样走人类盲测投票,比静态 benchmark 难刷分得多。Qwen3.7-Max 拿到 1541 分排全球第 2,前面只剩 Claude 系列那一档。GPT-5.5、Gemini 3.5 Flash 都在它后面。
阿里以前不是没冲过榜。Qwen3.6-Max-Preview 4 月在 Text Arena 上拿过第 3,但那是综合榜,里面 chat、写作、reasoning 摊薄了。Code Arena 这种纯编程加 agent 工具调用的子榜,国产模型从来没有摸到过 1541 这个位置。Artificial Analysis Intelligence Index v4.0 给的分是 56.6,也是国产模型历史最高。
但分数只是面子。Anthropic 自己出新版本,Code Arena 排名几周就洗一次牌。这次值得拉出来单写的是底下那个 demo。
Hero demo 是连续跑 35 小时、1158 次 tool calls,这个数据比分数更狠
阿里把整个 demo 复盘写在 blog 里,我读完三遍才确认数字是认真的。任务是在阿里自家 T-Head ZW-M890 PPU 上优化 SGLang 里的 Extend Attention Kernel。这颗芯片在模型训练数据里没出现过,对它来说是「day-zero unseen hardware」。
Qwen3.7-Max 跑了大约 35 小时,完成 1158 次 tool calls 和 432 次 kernel evaluations,最终拿到相对 Triton reference 10 倍的几何平均加速。同条件下其它模型对比也放出来了:
- GLM 5.1:7.3 倍
- Kimi K2.6:5.0 倍
- DeepSeek V4 Pro:3.3 倍
- Qwen3.6-Plus:1.1 倍
这些模型停下来的原因都一样:连续 5 轮没发起 tool call,模型自己得出结论「干不动了」然后退出。Qwen3.7-Max 跑到 30 小时还在找有意义的优化方向。
除了这个 hero demo,阿里在 Terminal-Bench 2.0 上拿到 69.7,超过 DeepSeek-V4-Pro 的 67.9 和 Qwen3.6-Plus 的 61.6。SWE-Bench Pro 60.6 也是国产历史最高。最离谱的是 YC-Bench 那条:阿里让模型模拟一年期 startup 经营,需要做人事决策、筛合同、辨识恶意客户、维持利润率。Qwen3.7-Max 跑出 $2.08M 模拟营收,是 Qwen3.6-Plus($1.05M)的 2 倍,Qwen3.5-Plus($352K)的 5.9 倍。
不夸张地讲,这是 Anthropic 之外第一次有公司公开把 30 小时以上单 session agent 跑通。阿里官方原话叫「Complex projects that typically require one to two weeks of specialized team effort can now be completed end-to-end within hours」,听起来像营销话术,但 35 小时加 1158 tool calls 是有数据兜底的。
国内开发者真正该关注的是价格:input $2.50、cached $0.25,比 Claude 便宜 6 倍
Qwen3.7-Max 的定价表是这样的:input $2.50、output $7.50(per 1M tokens),cached input 降到 $0.25。
Claude Opus 4.7 是 $15 input / $75 output。GPT-5.5 是 $10 / $30。Qwen3.7-Max 比 Claude 便宜 6 倍,比 GPT-5.5 便宜 4 倍。
便宜 6 倍这件事对长链路 agent 是杀招。你想象一下,1M context 铺满 codebase,前面 80 万 token 都进 cache,每轮调用走 $0.25 而不是 $2.50。一个 35 小时 agent 跑完,原来要花 $300 现在 $40 多就搞定。
国内创业团队这两年算 agent 账一直卡在「Claude 用得起 demo 用不起客户」。Qwen3.7-Max 第一次把这道账拉到了能跟客户报价的位置。我跟一个在做企业 agent 的朋友聊,他原话是:「之前我每个客户 demo 单次 token 成本 $5,跑长任务直接劝退老板。现在算下来 $0.8 一次,能直接打包卖了」。
Anthropic 协议兼容这一步棋下得有点意思
阿里这次最聪明的动作不在模型本身,在 API 兼容性。Qwen3.7-Max 原生支持 Anthropic 协议,你拿现有的 Claude Code,把 base URL 切到阿里云 dashscope,模型立刻能跑,一行客户端代码都不用改。
同时它也兼容 OpenAI 协议,Aider、Cursor、Cline 这些走 OpenAI SDK 的工具都能直接接。你 Claude Code 装得好好的,结果今天跑 Anthropic、明天跑 Qwen、后天跑 DeepSeek,客户端不用动。
说白了,阿里在 Anthropic 自建的 Claude Code 护城河上挖了一道暗渠。用户用着 Anthropic 的工具,下面跑的是 Qwen。这跟 OpenRouter 那种「我帮你做模型路由」是两回事。阿里直接在协议层把自己装成 Anthropic 的兼容供应商,等于在原产地复刻了一个 Claude API 出口。
我那个朋友补了一句:「我们公司禁海外 API 但允许接阿里云,现在 Claude Code 终于不用被组里 ban 了」。这种用户阿里直接收了一波。
实操层面其实很简单,Claude Code 配置文件里把 ANTHROPIC_BASE_URL 改成阿里云 dashscope 的 Anthropic 兼容入口(https://dashscope.aliyuncs.com/api/v2/apps/...),把 API key 换成阿里云的,模型名换成 qwen3.7-max,就跑起来了。Cursor 那边走 OpenAI 兼容设置类似,base URL 改一行就能用。整个切换成本几分钟,没有客户端代码改动。
Qwen3-Coder 和 Qwen3-Max 是两条产品线,国内圈很多人混着叫
写这篇之前我刷了一圈中文圈讨论,发现一半的人在把 Qwen3-Coder 和 Qwen3-Max 当一个东西聊。这俩完全是两条不同的产品线,得先分清楚。
Qwen3-Coder(旗舰版 480B-A35B)是 Qwen 团队的专用编程模型,open-weight、Apache 2.0 协议,你能下下来在自己机器上跑。Mac M3 Ultra 或者 Blackwell GB10 之类的高配硬件能本地拉起来,配 Cursor、Cline 当本地补全后端。
Qwen3-Max 是通用 agent 旗舰,闭源、API-only、目前没有开源计划。1M context、Anthropic 协议兼容、走的是云端长时程 agent 路线。你拿不到 weights,只能通过阿里云 Model Studio 调。
本地开发追求补全速度加数据不出门就选 Coder。Max 是另一条线,跑云端长时程 agent + 1M context 这类自部署跑不动的场景。两个都需要的话可以全接进 Claude Code 切着用。
35 小时 demo 是阿里自家数据,目前还没独立复现这条要先说清楚
前面的数字很猛,但有几条 caveat 我得先讲清楚。
35 小时跑 1158 次 tool calls 是阿里官方在自家芯片上跑的内部 demo。T-Head ZW-M890 是阿里自家芯片,SGLang Extend Attention Kernel 是阿里自家有深度参与的开源库。这个组合属于「模型加硬件加任务」全在阿里生态内部。截止到我写这篇文章,第三方实验室还没有人在中立环境下复现这个数字。
另外还有一条我特别在意。AA-Omniscience(factual recall benchmark)显示,Qwen3.7-Max 的 attempt rate 从 Qwen3.6-Plus 的 67.3% 跌到 48%。说人话就是模型变得更倾向于回答「我不知道」而不是硬猜。
这对 agent 长链路是好事,错答 100 个不如直接 abstain 50 个再答对 150 个。但对 QA、客服、文档检索类应用来说就是退步,你要的是答案而不是「我不知道」。所以这模型适不适合你的业务得看具体场景,不能只盯 1541 分这一个数字。
还有一条小坑要提,Qwen3.7-Max 是 text-only 模型。要图像理解你得另接 Qwen3.7-Plus(vision 配套版本)。我们项目里有不少 PDF 截图分析的场景,最后只能两个模型混着用,对 prompt orchestration 增加了点复杂度。
我下周一开始用 Claude Code 接 Qwen3.7-Max 跑一个 80 万 token 的长项目
光看官方 demo 没用,下周一开始我自己跑一遍。
任务是手头一个长期跑的中文文档分析项目,素材体量大概 80 万 token,过去一直靠 Claude Sonnet 分批处理。下周用 Claude Code 客户端,base URL 切到阿里云 dashscope,模型用 Qwen3.7-Max。两个关心的点:
cached input 在 80 万 token 这个量级上实际命中率多少。官方说 $0.25 / 1M token,但实测能不能稳住缓存命中是另一回事,长 prompt cache 跟 Anthropic 的实现机制不一定一样。
长链路 agent 连续跑 4 到 5 小时不掉链稳不稳。35 小时是 hero demo 数据,普通用户在普通任务上能不能复现这个稳定性才是真考验。
跑完写一篇实测对比报告。如果你在等这种实测内容,留言里说一下你最想看哪个维度,我跑的时候会重点测一下。