每次跟 AI 聊天都在花钱?一文搞懂 Tokens 到底是什么
你有没有注意过,ChatGPT、Claude 这些 AI 工具的定价页面上,写的都是”每百万 tokens 多少钱”?
第一次看到这个词的时候,我也懵了。什么是 token?为什么不直接按字数收费?输入 token、输出 token、缓存 token 又是什么鬼?
后来搞明白之后我才意识到:理解 tokens,是理解 AI 定价的钥匙。 不懂 tokens,你就不知道自己的钱花在了哪里,更不知道怎么省钱。
Token 是什么?一个比方就够了
先忘掉所有技术术语。
想象你去一家餐厅点菜。菜单上的价格不是按”一道菜”标的,而是按”食材克数”标的。你点了一份红烧肉,厨房不看”这是一道菜”,而是拆开看——猪肉 200 克、酱油 30 毫升、糖 15 克——然后按食材的总量给你算钱。
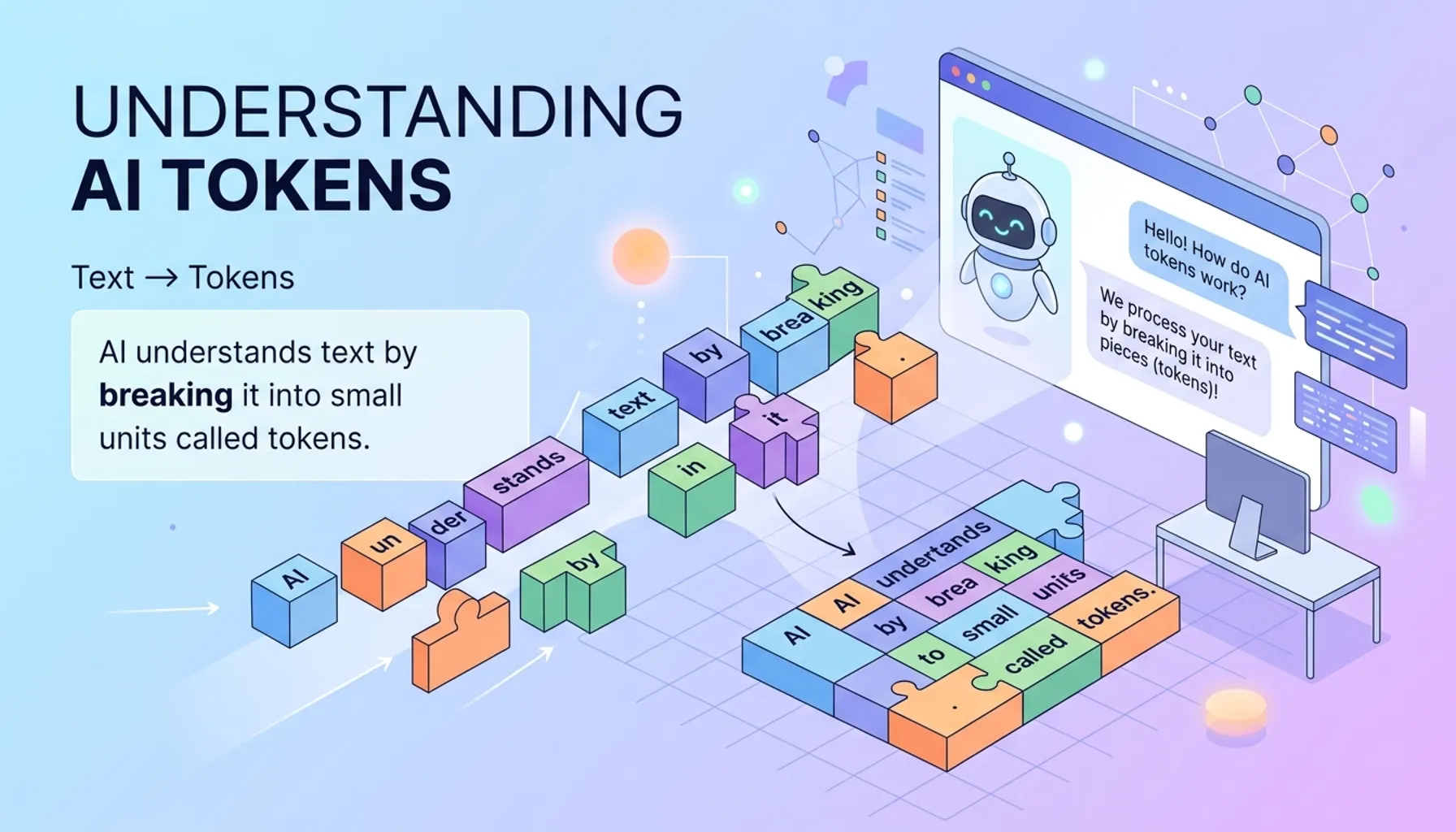
Token 就是 AI 世界里的”食材克数”。
你发给 AI 的每一句话,AI 不是”读一句话”,而是先把这句话拆成一个一个的小碎片——这些碎片就叫 token。AI 按 token 的数量来计算工作量和费用。
举个例子:”我想学编程” 这五个汉字,大概会被拆成 3-5 个 token。”I want to learn programming” 这句英文,大概是 5-6 个 token。
一个粗略的换算:
- 英文:1 个 token ≈ 0.75 个单词(4 个字母左右)
- 中文:1 个 token ≈ 1-2 个汉字
所以中文用户要注意——同样的意思,中文消耗的 token 数量通常比英文多。
为什么 AI 要用 Token,不直接用”字”?
你可能会问:干嘛搞这么复杂,直接按字数收费不好吗?
因为 AI 不认识”字”。
AI 的大脑是一个数学模型,它只能处理数字。所以在处理你的文字之前,必须先把文字转换成数字。这个转换的过程叫做分词(tokenization)。
NVIDIA 的技术博客举了一个很直观的例子:英文单词 “darkness” 会被拆成两个 token——“dark”(编号 217)和 “ness”(编号 655)。而 “brightness” 也被拆成 “bright”(编号 491)和 “ness”(编号 655)。
注意到了吗?**”ness” 的编号是一样的。** 这就是 token 的聪明之处——通过共享的编号,AI 学会了 “darkness” 和 “brightness” 之间有某种结构上的关系。如果按整个单词来编号,AI 就发现不了这种规律。
所以 token 不是 AI 故意为难你,而是它理解世界的方式。
三种 Token:输入、输出、缓存
现在你知道 token 是什么了。但在实际使用中,token 还分三种类型,价格各不相同。
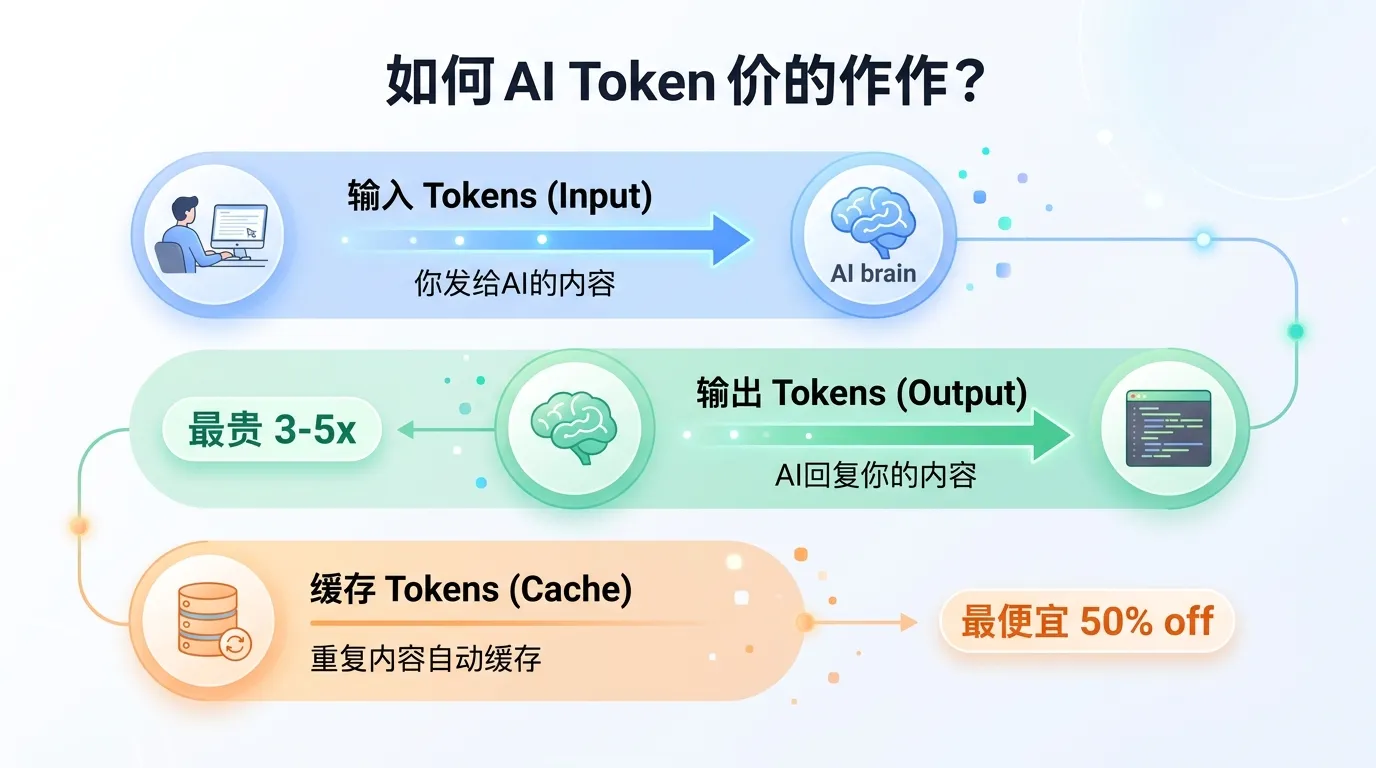
输入 Token(Input Tokens)
你发给 AI 的所有内容,都算输入 token。
包括:你打的文字、上传的文件、贴的图片、系统提示词(system prompt),甚至之前的对话历史——全部都要转成 token 喂给 AI。
但这里有一个坑,我一开始也不知道:AI 的 API 是无状态的。 什么意思?就是 AI 其实不记得你之前说了什么。每次你发新消息,系统都会把之前所有的对话历史重新发一遍。
FinOps 基金会管这个叫 “上下文窗口蔓延”(Context Window Creep)——随着对话越来越长,每发一条新消息,重复发送的历史内容就越多,输入 token 像滚雪球一样越来越大。
这就是为什么你聊到后面会觉得越来越贵、速度越来越慢。
输出 Token(Output Tokens)
AI 回复你的内容,就是输出 token。
输出 token 是最贵的——通常是输入 token 价格的 3 到 5 倍。
为什么?因为生成回复比理解问题消耗的算力大得多。读一篇文章和写一篇文章,哪个更累?写当然更累。AI 也一样。
看一组真实价格对比(2026 年 3 月数据):
| 模型 | 输入价格(每百万 token) | 输出价格(每百万 token) |
|---|---|---|
| GPT-4o | $2.50 | $10.00 |
| Claude Sonnet 4.6 | $3.00 | $15.00 |
| Claude Opus 4.6 | $5.00 | $25.00 |
一眼就能看出来——输出永远比输入贵。 所以如果你希望 AI 写一篇 5000 字的长文,那个输出 token 的账单会很可观。
缓存 Token(Cached Tokens)
如果你发送的内容跟上次有大量重复,重复的部分可以走缓存,价格便宜一半甚至更多。
举个例子:你用 AI 写代码,每次都会带上同样的系统提示词(比如”你是一个 Python 专家,代码要简洁”)。这段提示词第一次发送时是普通输入 token,但从第二次开始,AI 发现”这段我刚处理过”,就会自动缓存,按更便宜的价格计费。
以 OpenAI 的定价为例:
- 普通输入:$2.50 / 百万 token
- 缓存输入:$1.25 / 百万 token(半价)
Anthropic 的缓存更狠——缓存命中的价格只有正常输入的 **10%**。
简单说:用法越固定、重复越多,缓存省得越多。 这对写代码的开发者来说是个好消息——你的系统提示词和项目上下文天然就是高度重复的。
一个真实场景:你跟 AI 聊 10 轮,到底花了多少 token?
说了这么多概念,来算一笔真实的账。
假设你跟 AI 聊天,每轮你说 100 个 token,AI 回复 300 个 token。
| 轮次 | 输入 token(含历史) | 输出 token | 累计输入 |
|---|---|---|---|
| 第 1 轮 | 100 | 300 | 100 |
| 第 2 轮 | 500 | 300 | 600 |
| 第 3 轮 | 1,100 | 300 | 1,700 |
| 第 5 轮 | 2,900 | 300 | 6,600 |
| 第 10 轮 | 6,700 | 300 | 30,900 |
看到没有?到第 10 轮的时候,单次输入就要 6700 个 token——其中绝大部分是重复发送的历史对话。 累计输入已经超过 3 万 token 了。
这就是”上下文窗口蔓延”的威力。你以为自己只打了 1000 个字,实际上 AI 处理了 3 万多个 token。
省 Token 的实用技巧
明白了 token 的运作方式,省钱就有了方向。我自己踩了不少坑之后,总结出几条最管用的。
话题一换就开新窗口
这是效果最立竿见影的一条。上面那个 10 轮对话的表格已经说明了——对话越长,每轮重复发送的历史越多,token 消耗指数级增长。我以前习惯在一个窗口里从早聊到晚,后来看了一次 API 账单才发现,最后几轮每条消息的 token 消耗是第一轮的几十倍。现在我的习惯是:话题一变就开新对话,绝不留恋。
需求一次说清楚,别挤牙膏
这条也是血泪教训。很多人(包括以前的我)习惯这样跟 AI 聊:
“帮我写个函数”
“用 Python”
“要处理 JSON”
“加上错误处理”
四轮对话,四次重复发送历史。换成一句话:
“用 Python 写一个处理 JSON 的函数,包含完整的错误处理”
一轮搞定,token 消耗立刻降到四分之一。把 AI 当一个刚入职的同事——你交代任务的时候,一次说清楚比让人来回问强。
控制输出长度
输出 token 最贵,这条很多人忽略了。AI 默认会尽量详细地回复,你不限制它就会一直写。所以如果你只需要一个简短的答案,明确告诉它:”用三句话总结”比”帮我总结一下”省钱得多。
其他几条也值得知道
选对模型。 简单的问答、翻译、格式转换,用 GPT-4o-mini 或者 Claude Haiku 就够了,价格只有旗舰模型的几十分之一。我的经验是先用便宜模型试,不满意再换贵的——80% 的日常任务,便宜模型完全能搞定。
别贴无关内容。 你贴给 AI 的每一个字都在消耗 token。只贴相关的部分,把无关内容删掉再发。
用英文提问可以省 30%-50% 的 token。 同样的意思,中文比英文消耗更多 token。当然如果你需要中文回复,省下的输入可能被输出吃掉,具体看情况。
通过 API 调用的话,善用系统提示词缓存。 把不变的提示词放在最前面,更容易命中缓存,享受半价甚至更低的价格。
写在最后
Token 听起来是一个技术概念,但它其实就是 AI 世界的”度量衡”——就像用水按吨计费、用电按度计费一样,用 AI 按 token 计费。
我上个月的 Claude 账单是 87 美元,其中大概有三分之一是”上下文窗口蔓延”贡献的——就是那些重复发送的对话历史。搞清楚这件事之后,我养成了两个习惯:话题一换就开新窗口,需求一次说完不分三条发。光这两个改变,这个月的消耗就降了 40% 左右。
而且省 token 不光省钱,AI 的回复质量也会更好——上下文越干净,它越不容易跑偏。这可能是最划算的”免费升级”了。
你每个月在 AI 工具上花多少钱?有没有注意过自己的 token 消耗?评论区聊聊你的使用习惯。