AI 的"记忆力"有多大?200K 和 1M 上下文到底差在哪
上一篇文章讲了 token 是什么,很多人在评论区问:那”上下文窗口”又是什么?200K 上下文和 1M 上下文有什么区别?
这个问题问得好。如果说 token 是 AI 的”计费单位”,那上下文窗口就是 AI 的”工作记忆”——它决定了 AI 一次能”记住”多少东西。
今天这篇文章,我用最直白的方式把上下文窗口这件事讲清楚。
上下文窗口是什么?一个比方就懂了
我跟朋友聊天的时候发现一个事——聊了半小时之后,话题从天气聊到工作,从工作聊到周末计划。我说”所以我觉得还是算了”,他立刻就知道我说的是周末爬山那事。这就是上下文的作用。
上下文窗口,就是 AI 的”聊天记忆容量”。
但 AI 的记忆跟人不一样。人的记忆是模糊的、有选择性的——你会记住重点,忘掉细节。AI 的记忆是精确的、机械的——它要么记住所有东西,要么什么都不记得。
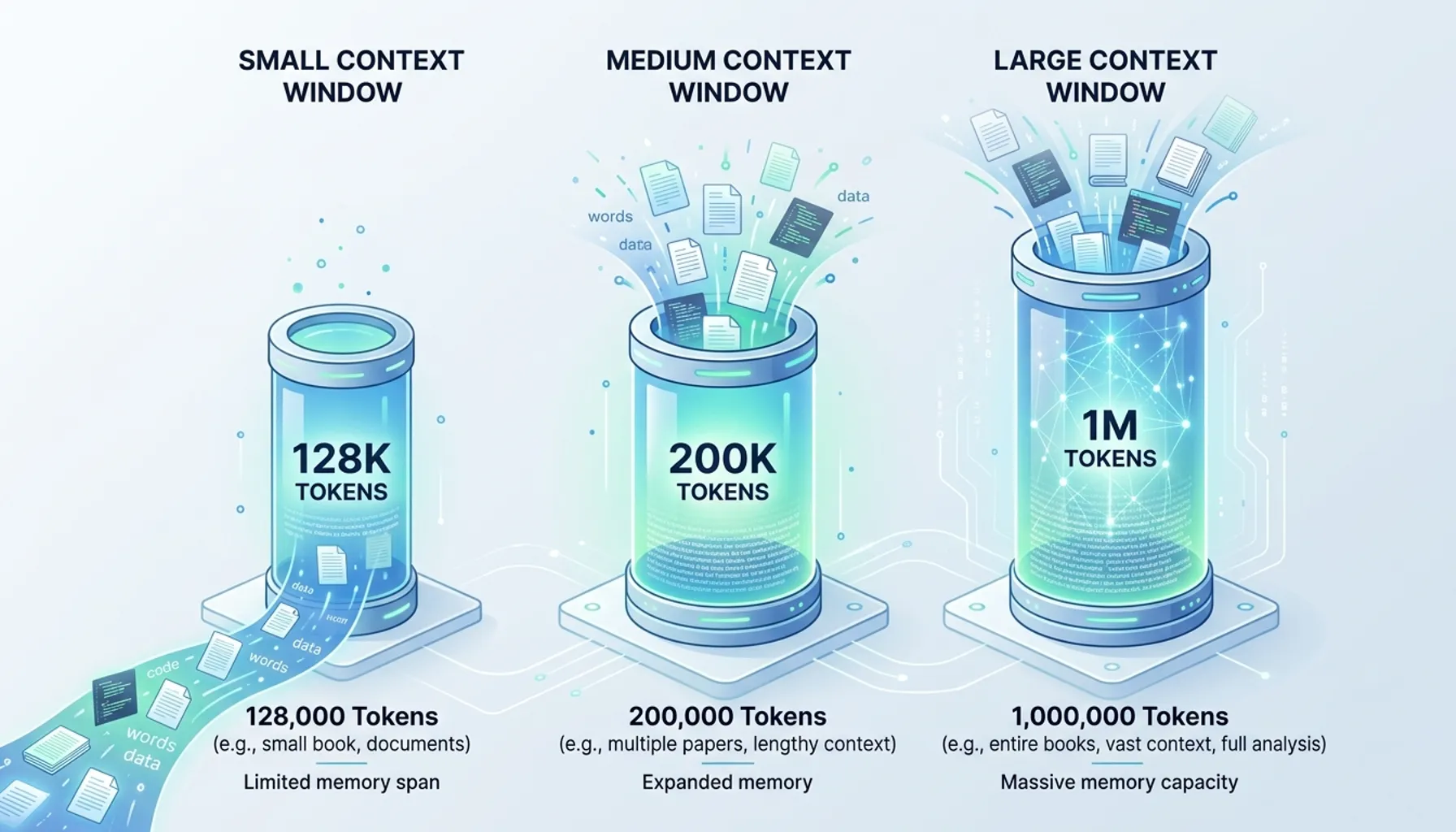
上下文窗口的大小,用 token 来衡量。比如:
- 128K 上下文 = 能记住大约 128,000 个 token
- 200K 上下文 = 能记住大约 200,000 个 token
- 1M 上下文 = 能记住大约 1,000,000 个 token
换算成人话:
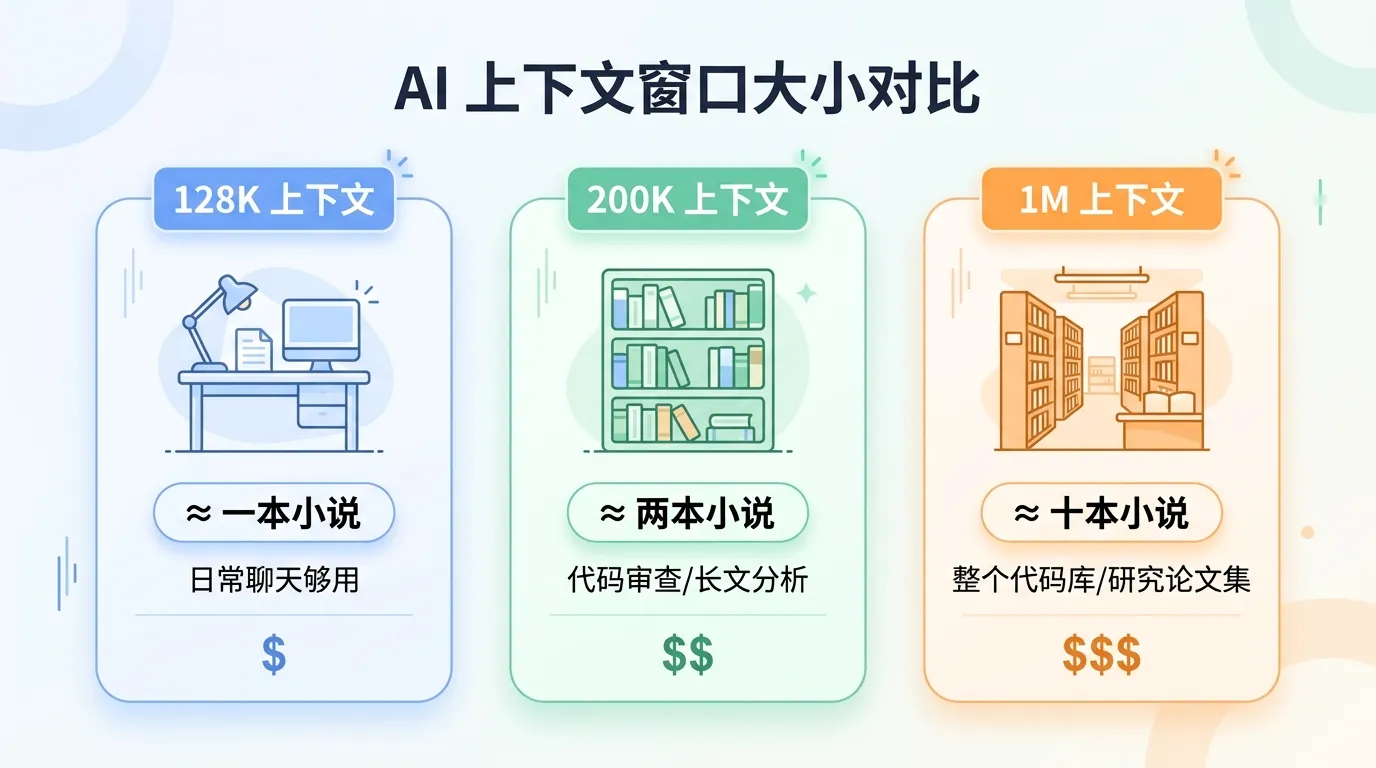
- 128K ≈ 一本中等长度的小说(10 万字左右)
- 200K ≈ 两本小说
- 1M ≈ 十本小说
为什么上下文窗口很重要?
因为它决定了 AI 能处理多复杂的任务。
上周我想让 AI 总结一篇 5 万字的研究报告,结果发现它只有 32K 上下文(大约 2.4 万字)——根本装不下。我得把文章拆成三段,分别喂给它,然后自己把三段总结拼起来。要是它有 200K 上下文,一口气就能读完。
写代码的时候也一样。我用 Claude Code 重构一个项目,50 个文件,总共 15 万个 token。如果 AI 只有 128K 上下文,它只能看到其中一部分文件——改着改着就忘了另一半代码长什么样,容易改出 bug。但如果有 200K 上下文,它能把整个项目装进脑子里,改起来就不容易出错。
还有长对话的问题。你跟 AI 聊了 20 轮,每轮你说 100 个 token,AI 回 300 个 token。到第 20 轮的时候,历史对话已经累积了 8 万个 token。如果 AI 只有 32K 上下文,到第 8 轮就装不下了——它会自动”忘掉”最早的几轮对话,突然不记得你们之前聊了什么。
200K 和 1M 上下文,实际体验差多少?
2026 年 3 月,主流 AI 模型的上下文窗口大概是这样的:
| 模型 | 上下文窗口 | 适合场景 |
|---|---|---|
| Claude Opus 4.6 | 200K | 代码审查、长文分析、复杂对话 |
| GPT-5.2 | 400K | 多文档对比、大型项目重构 |
| Gemini 3 Pro | 10M | 整个代码库分析、研究论文集 |
乍一看,1M 比 200K 大五倍,应该好用五倍吧?
实际上没那么简单。
1M 上下文的三个坑
性能会下降。
NoLiMa 研究发现,当上下文超过 32K token 的时候,12 个主流模型里有 11 个的表现会掉到短上下文时的 50% 以下。上下文越大,AI 越容易”找不到重点”。
就像你让一个人在一个图书馆里找一本书,比在一个书架上找要慢得多——信息太多反而干扰判断。
价格会翻倍。
很多人不知道的是:超过 200K 之后,token 价格会涨。
以 Gemini 为例:
- 前 200K token:正常价格
- 超过 200K 的部分:价格翻倍
所以如果你用 1M 上下文,实际花的钱可能是 200K 的 2-3 倍,而不是 5 倍——但也不便宜。
你可能用不到那么大。
Reddit 上有个讨论很有意思:一个开发者说”我的经验是,1M 上下文的模型在填满 40% 之后就开始跑偏,经常忘记自己在干什么。”
另一个人回复:”我还是更喜欢 200K 的模型。虽然容量小,但它在整个窗口范围内表现都很稳定。”
这就是工程上的权衡——不是越大越好,而是够用就好。
上下文大小和 Token 消耗速度的关系
上下文窗口大小不会直接影响 token 消耗速度——这点很多人不知道。
什么意思?
假设你跟 AI 聊天,每轮你说 100 个 token,AI 回 300 个 token。不管 AI 的上下文窗口是 200K 还是 1M,这一轮消耗的 token 数量都是 400 个——跟窗口大小没关系。
但是,上下文窗口会间接影响你的消费习惯。
如果你知道 AI 有 1M 上下文,你可能会:
- 一次性贴更多文件进去(”反正装得下”)
- 不开新对话(”还有空间,继续聊”)
- 不删无关内容(”懒得整理了”)
结果就是:你的每一轮对话都在处理更多 token,账单自然就上去了。
真实案例:
我之前用 Claude Opus(200K 上下文)写代码,习惯每完成一个功能就开新对话。后来换成 Gemini(1M 上下文),觉得”反正装得下”,就一直在同一个窗口里聊。
一个月后看账单,Gemini 的消费比 Claude 高了 60%——不是因为 Gemini 贵,而是因为我用它的方式变了。
怎么选上下文窗口?
根据 2026 年的实际使用经验,我的建议是:
日常聊天、简单问答 → 128K 够了
如果你只是问问题、翻译、写邮件,128K 完全够用。省钱,速度还快。
代码审查、长文分析 → 200K 是甜蜜点
200K 是目前性价比最高的选择。能装下一个中型项目的代码,或者两三篇长文,而且模型表现稳定。
Claude Opus 4.6 的 200K 上下文,在整个窗口范围内表现都很一致——不会因为内容多了就开始犯糊涂。
整个代码库分析、研究论文集 → 才需要 1M
只有在你真的需要一次性处理海量信息的时候,1M 上下文才有意义。比如:
- 分析一个有几百个文件的大型项目
- 对比十几篇研究论文
- 处理一整本书的内容
但即使在这些场景下,也要注意:别把所有东西都塞进去。 只放相关的部分,AI 的表现会更好。
一个省钱又好用的技巧
不管你用多大的上下文窗口,有一个技巧永远有效:话题一换就开新对话。
为什么?
因为 AI 是无状态的——每次你发新消息,它都会重新读一遍所有历史对话。对话越长,重复处理的 token 越多,消耗越大。
我现在的习惯是:
- 写完一个功能 → 开新对话
- 聊完一个话题 → 开新对话
- 切换任务 → 开新对话
这样做不光省钱,AI 的回复质量也更好——因为上下文干净,它不容易被无关信息干扰。
写在最后
上下文窗口听起来是个技术指标,但它其实就是 AI 的”工作记忆”。
128K、200K、1M 的区别,不只是数字大小,更是使用场景和成本的权衡。大部分人大部分时候,200K 就够了——能装下足够多的信息,价格合理,表现稳定。
1M 上下文很诱人,但别被”越大越好”的直觉骗了。上下文太大,AI 容易跑偏,价格也会翻倍。够用就好,别贪多。
最后一个建议:不管你用多大的上下文,都要养成”开新对话”的习惯。这是最简单也最有效的省钱方式——而且 AI 的回复质量也会更好。
你平时用的 AI 是多大的上下文窗口?有没有遇到过”上下文不够用”或者”上下文太大反而变笨”的情况?评论区聊聊。