零费用本地跑 AI:我用 Ollama + gemma4:e4b 写了个计算器,踩了这些坑

哈喽,我是飞飞。
上个周末,我盯着账单坐了好一会儿。
这个月光 Claude API 和 OpenAI 的调用费,加起来比我预想的多不少。我已经刻意克制了——不跑没必要的任务,能用免费额度就不动 API。但账单还是比上个月涨了。
我就想:能不能搭一套完全不烧钱的本地 AI 开发环境?
然后我花了半小时,用 Ollama + Claude Code + gemma4:e4b,把一个计算器跑起来了。
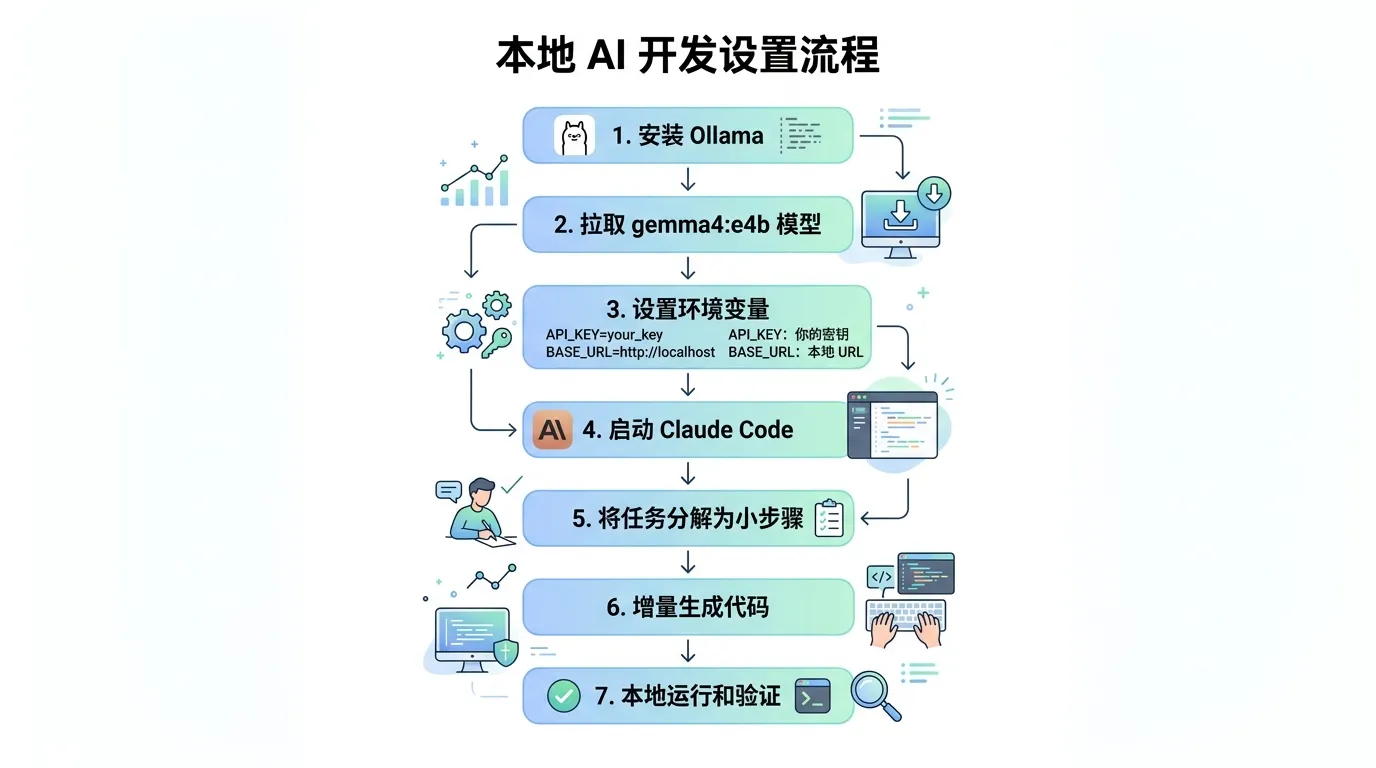
为什么选 Ollama
我之前用过 LM Studio,界面好看,但总感觉太「重」。
Ollama 的设计哲学更接近 Docker——一个命令拉模型,一个命令跑起来,REST API 直接暴露在 11434 端口。你甚至不需要打开任何 UI。
1 | # 安装完之后,拉一个模型就这一行 |
跑起来之后,Ollama 在本地开了个 API 接口,同时兼容 OpenAI 和 Anthropic 两种格式。也就是说,你原有的代码不用动,把 base_url 从 api.openai.com 换成 localhost:11434,就切过来了。
我之前以为切换本地模型要改很多代码。实际上换了那一行,项目照样跑,没有任何报错。
为什么选 gemma4:e4b
其实我一开始想跑 gemma4 的 26B 版本,但我的 MacBook Pro 撑不住。
我在 Ollama 的模型库里翻了一圈,最后卡在 e4b 这个名字上——E 代表 effective parameters,推理时只激活 4.5B 有效参数,比同量级的模型显存占用小很多,我的 MacBook Pro 能撑住。
更关键的是两点:它支持函数调用,上下文窗口 128K。没有函数调用,Claude Code 就是个聋子,读文件、写代码、执行命令这些工具它都调不了;128K 的上下文窗口意味着我写了两百行代码之后,模型不会突然「失忆」,忘了开头在干什么。Apache 2.0 协议我倒不怎么在意,主要是不想被 license 限制折腾。
把 Claude Code 接上本地模型
这一步出乎意料地简单。
Ollama v0.14.0 之后加了对 Anthropic Messages API 的兼容,官方直接提供了对接 Claude Code 的文档。我只需要设置两个环境变量:
1 | export ANTHROPIC_AUTH_TOKEN=ollama |
然后正常启动 Claude Code,指定模型名:
1 | claude --model gemma4:e4b |
Claude Code 的界面就起来了,后面接的是我本地的 gemma4:e4b,一行 API 调用费都没有。
我当时在终端里盯着那个交互界面,有点不敢相信这真的在本地跑。
开发计算器的过程
我选计算器不是因为它有多厉害,而是因为它足够小。
本地模型的能力终究有限,我不想在一个复杂项目上撞墙。计算器让我把精力放在工具链本身——搭环境、调参数、理解模型的行为边界——而不是陷入业务逻辑的泥坑里。
我的提示词很简单:
帮我开发一个简单的计算器,支持加减乘除等功能。
第一次输出还不错,基本结构都有,大概长这样:
我一看,这不就是 iPhone 上的系统计算器嘛,你俩长得挺像的。
测试的时候,有点问题,然后我让它优化,加上输入校验,避免 eval 的安全问题。
这里出现了第一次卡顿。
模型生成到一半停住了,然后重新开始输出前面已经写过的内容。我等了大概 40 秒,发现它在兜圈子。
我后来查了一下,这是小模型在 Claude Code 场景下的常见问题——上下文一长,它就容易找不到方向。降低 temperature、缩短单次上下文可以缓解,但不能完全解决。
我选择了一个折中方案:把任务拆得更细,每次只让它做一件事。
1 | 第一步:只写解析表达式的函数 |
这种方式下,gemma4:e4b 的表现稳定多了。最终计算器顺利跑起来,支持括号嵌套、错误提示、循环输入,代码大概 60 行。
本地模型 vs 云端:真实感受
跑完之后我打开了那张账单,API 那一栏还是 ¥0。
这种感觉比「省钱」更准确。它让我意识到,之前那些「算了别试了,要花钱」的念头,其实根本没必要。实验性的项目、学一个新工具、跑个草稿——这些场景,本地模型完全够用,而且不用在意每次调用消耗了多少 token。
另一件触动我的事是高铁那次。我上高铁想用 Claude Code 处理点东西,结果没信号,直接废掉了。那时候我意识到自己对云端有多依赖——它断了,工作也断了。本地模型不依赖网络,这不是什么锦上添花的特性,是真实的差异。
但要说局限,也是真实的。
gemma4:e4b 在我的 M1 MacBook Pro 上大概每秒 20-40 个 token,云端 Claude 快多了。复杂任务它容易卡壳,调试起来也麻烦——出了问题,你不知道是模型能力不够,还是参数没配对,还是 Claude Code 的上下文管理出了问题。
20-40 token/s 的速度,说实话,真正要写好代码的时候我还是会切回云端——但这已经比我预期的强太多了。我之前以为本地模型只适合玩玩,现在改变主意了:只要任务不超过它的能力边界,它比云端更好用,因为它不会在你最需要的时候突然断网。我现在的分法很简单——实验、学习、小任务给本地;需要真正写好代码的复杂任务,切云端。
几个实用配置建议
踩过的坑,记一下:
1. 上下文窗口要手动配置
Ollama 默认的上下文窗口不一定是满的。我最开始没配,Claude Code 跑着跑着就出现奇怪行为——模型开始重复生成已经写过的函数。加了这一行之后,稳定多了:
1 | PARAMETER num_ctx 32768 |
至少 32K,Claude Code 才能正常理解上下文。
2. 把 temperature 调低
我最开始没动 temperature,gemma4:e4b 在写输入校验那段时,突然开始给我加一个完全没要求的「历史记录」功能,自顾自地发散。调到 0.8 之后,它老实多了,只做我要求的那件事。代码生成场景推荐 0.7-0.85。
3. 每次只让它做一件事
这是帮我最大的一条。模型卡壳的根本原因,是我的 prompt 太大了——一次让它处理校验、安全、输出格式、错误提示,它就开始兜圈子。拆成四个 prompt 之后,每个都跑得很干净。我用 Claude Code 最大的价值,其实是它帮我拆任务,而不是指望本地模型一步到位。
4. 先从小项目开始
不是建议,是我自己的顺序。计算器跑通了,你对这套工具链的脾气就摸清了。下一个项目可以稍微大一点,但不要一上来就搭复杂系统——本地小模型不是不行,是你得先搞清楚它的边界在哪。
写在最后
我之前每次想「本地跑模型」,脑子里浮现的是:CUDA、驱动、兼容性报错、Stack Overflow、半天配不好。最后一般以「算了,直接用 API」收场。
这次花了一个下午,环境搭好了,计算器跑起来了,账单是 ¥0。
不是说本地模型已经很强了——该卡的地方还是会卡。但工具链成熟程度超出我的预期。两个环境变量,Claude Code 就接上本地模型了。这在一年前根本不是这个体验。
后来我又打开了那张账单。Claude API 那一栏还是 ¥0。我在那里盯了两秒,觉得有点爽。
我现在最想知道的是:有没有人在 Windows 上用 Ollama 跑 Claude Code,速度差多少?还有就是 gemma4 的 12B 版本——我的 Pro 跑不动,但如果有人测过和 e4b 的实际差距,评论区说一声。