用 Claude Code 写一篇文章,我省了一半的钱
大家好,我是飞飞。
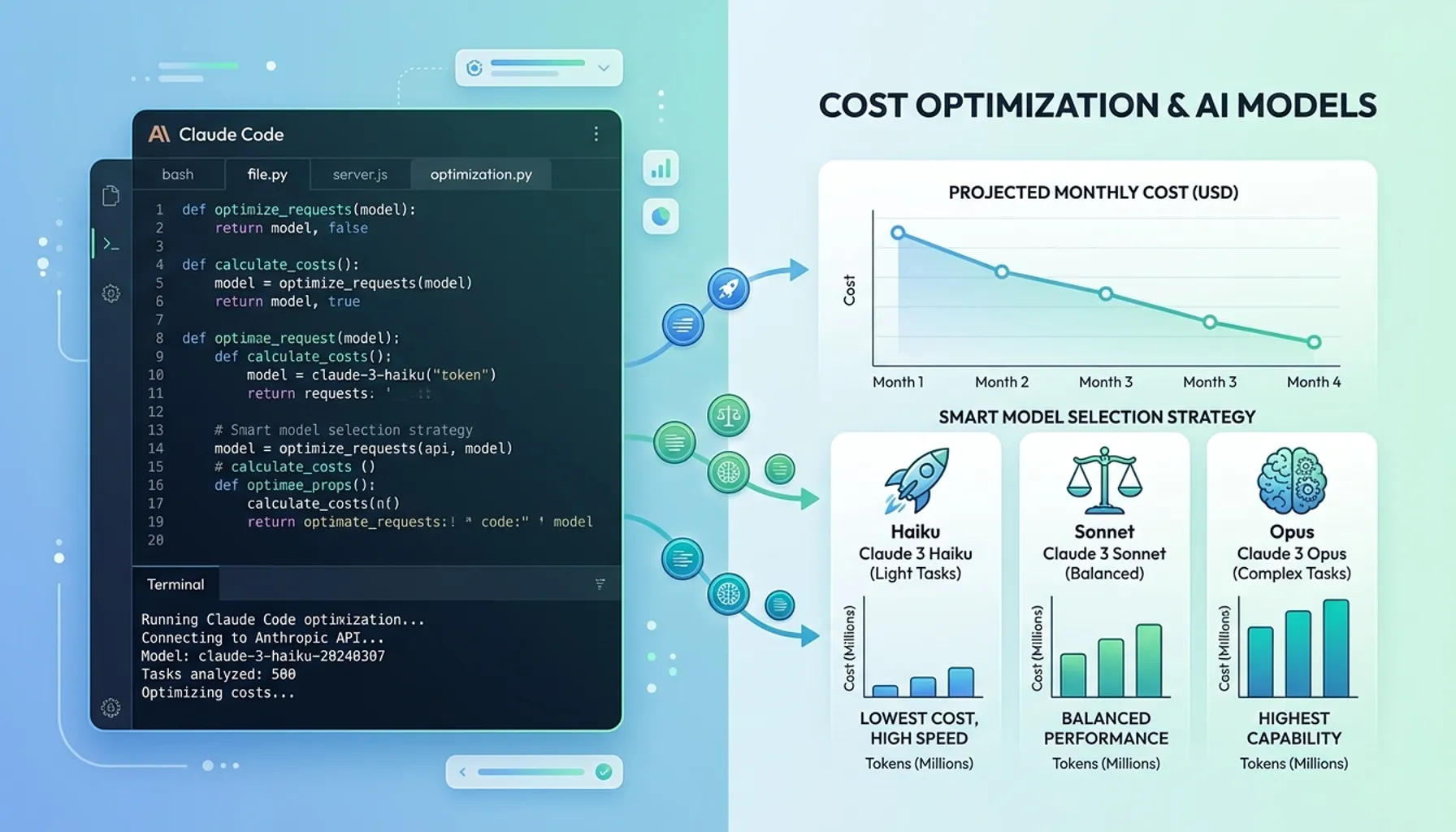
上周五晚上,我在刷 Anthropic 账单的时候发现,4月份头一篇文章跑完整条流水线,直接吃掉了 19% 的月度额度。
我用的是 Max 计划,$100/月。就是说,写这一篇博文花了我 $19。
我当时的第一反应不是”啊这也行”,是真的有点坐不住——上个月刚因为订阅这个计划跟自己较劲了半天,结果第一篇就烧这么多?
我有一条 6 个 Skill 的写作流水线
我搭了一套 Claude Code 的博客创作流水线,从找资料到发布,基本是全自动的:
1 | content-researcher → content-writer → content-polisher |
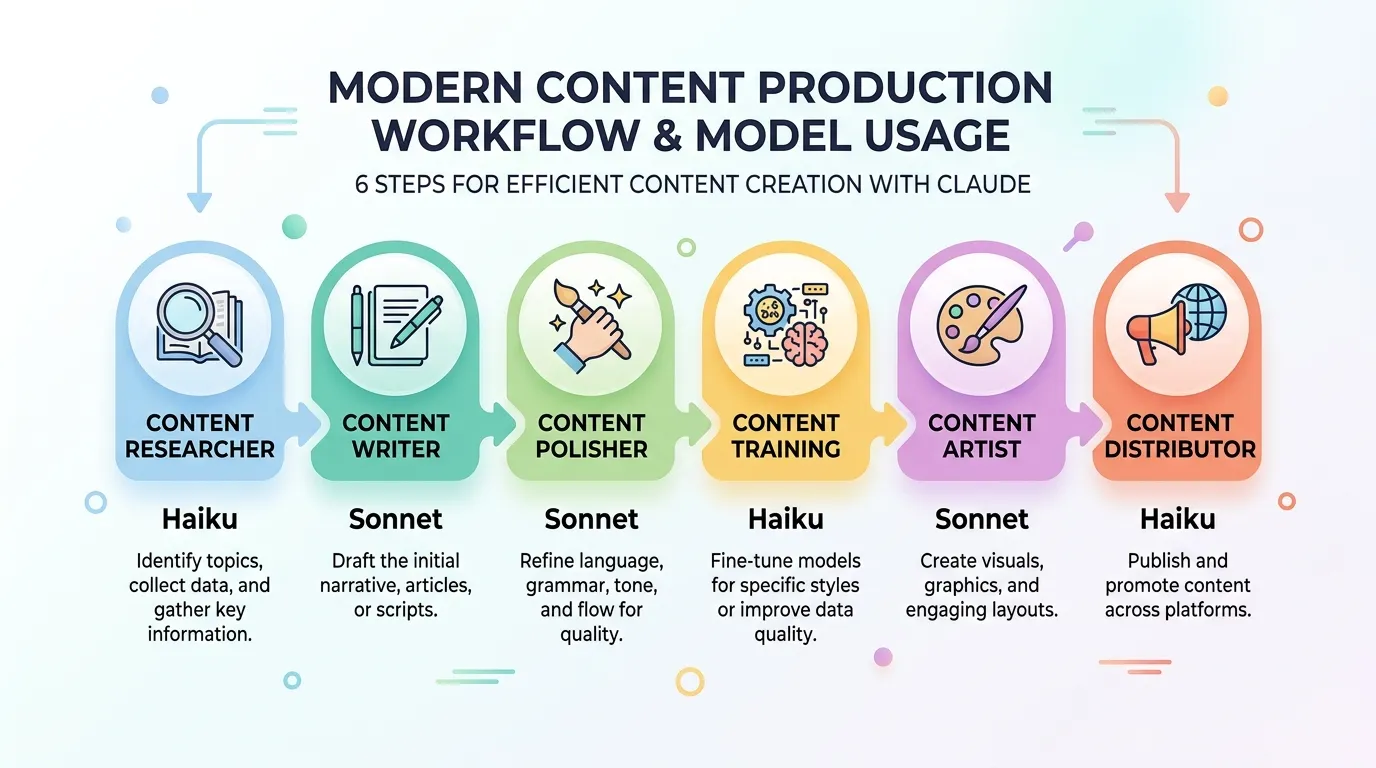
每个 Skill 做一件事:researcher 负责搜资料,writer 写文章,polisher 打磨语言,training 记录改进经验,artist 生成封面图,distributor 分发到各个平台。
这条流水线我挺满意的,一篇文章从选题到发布基本不用我动手。但我搭的时候图省事,6 个 Skill 全部用的 Sonnet,压根没想过这件事。
问题出在哪?Sonnet 处理每件事,但不是每件事都值 Sonnet
先看一下 Anthropic 的定价:
| 模型 | 输入价格 | 输出价格 |
|---|---|---|
| Haiku 4.5 | $1/MTok | $5/MTok |
| Sonnet 4.6 | $3/MTok | $15/MTok |
| Opus 4.6 | $15/MTok | $75/MTok |
Haiku 的输出成本是 Sonnet 的 1/3。Opus 是 Sonnet 的 5 倍。
我拿 content-researcher 举例。它的任务是:打开浏览器,搜几个关键词,抓取网页内容,整理成结构化的素材。这是体力活,没有太多推理,也不需要特别强的语言能力。
但我给它用的是 Sonnet。
再看 content-artist,任务是生成文章封面图:读取文章标题、提取关键词、调用图像 API、上传图片。同样是机械性操作,大量 token 消耗在处理图片路径和 API 参数上。
还是 Sonnet。
6 个 Skill 全用 Sonnet,content-researcher 帮我搜几个关键词、抓几个网页,这活儿用 Sonnet 来干……我现在想想都觉得有点离谱。
我怎么改的
Claude Code 的 Agent 子代理支持指定 model 参数,改起来不复杂,就是得想清楚哪些 Skill 真的需要 Sonnet,哪些其实 Haiku 就够了。
我自己划了一条线:需要写字、需要语感判断的,用 Sonnet;只是在搬运数据、调 API 的,用 Haiku。
具体下来是这样分的:
Sonnet:
- content-writer:这个必须,文章质量直接跟模型能力挂钩
- content-polisher:改语气、改措辞,也需要真的理解上下文
Haiku:
- content-researcher:搜词、抓网页、整理素材,执行性的活
- content-training:读记录文件、归纳、追加写入
- content-artist:提取标题关键词、调图像 API、上传图片
- content-distributor:格式转换、发布到各平台
改完之后跑了两篇文章,消耗降到 8-9%,从 $19 掉到大概 $10。没花多少时间,就改了几行配置。
顺手调了几个其他地方
模型选型改完之后,我又顺着查了一遍,发现还有几个地方也在漏。
Extended Thinking 开多了
Claude Code 的 Extended Thinking 默认预留 31,999 token 的思考空间。我之前没管过这个参数,就让它跑。后来测了一下,简单任务实际用到的不到 1/5,剩下 4/5 是白烧的。现在我一般设到 8000,只有做架构设计或者复杂 debug 的时候才开满。
CLAUDE.md 臃肿了
我的这个博客项目的 CLAUDE.md 被我写了不少”背景介绍”,每次会话启动都会加载进上下文,白白多付钱。剪掉了一批常识性的描述之后,减了大概 40%。
没配 .claudeignore
这个是我没想到的。项目目录里有 node_modules 和 public(Hexo 生成的静态文件),我没有排掉它们,Claude 搜代码的时候会扫进去。加了 .claudeignore 之后,响应速度也肉眼可见快了一些。
会话上下文没清理
我之前一个会话会一直用下去,从搜资料一路到发布,历史越堆越长,后面每次请求都带着前面几千 token 的历史。现在改成写完一个阶段就 /compact,切换任务就 /clear。感觉是最容易被忽视的地方。
提问太模糊
“帮我看看这个文件”和”帮我检查 src/utils/parser.ts 第 50-80 行的错误处理逻辑”,token 消耗差的不是一点半点。前者 Claude 要先把整个项目扫一遍才知道你在说哪里。现在问问题我会尽量带上具体路径和行号。
子代理默认模型
设一个环境变量 CLAUDE_CODE_SUBAGENT_MODEL=claude-haiku-4-5,所有子代理默认跑 Haiku,需要更强的时候再单独指定。这个是全局兜底,避免哪个地方漏配了。
现在消耗大概是多少
把这些地方都调了之后,我自己跑了几篇:
- 之前:一篇文章 ~19%,约 $19
- 现在:一篇文章 ~8-9%,约 $8-9
差不多砍了一半出头。
Reddit 上也有人发过对比数据,没有优化习惯的用户日消耗在 $20-40,有习惯的在 $5-15。我自己的感觉跟这个区间差不多对得上。
最值的两件事,我觉得是模型按任务选型和上下文随时清理,其他几个是补充。如果你只想改一件事,先从模型选型开始。
说实话,这件事让我有点警觉——我搭流水线的时候专注在”能不能跑通”,完全没想过”跑通之后在烧什么”。自动化流程跑起来之后反而更不容易发现这类问题,因为你不会每次都盯着账单看。
如果你也在用 Claude Code 搭工作流,建议第一件事就是去看看各 Skill 的模型配置。很可能有几个根本不需要 Sonnet 的地方在默默帮你花钱。
你有遇到过账单超出预期的情况吗?欢迎留言,我想看看大家踩的坑有没有比较集中的地方。