Karpathy 的 LLM Wiki:让 AI 帮你把读过的文章变成复利
大家好,我是飞飞。
上周我做了一件蠢事。
我让 Claude 帮我整理两个月前读过的一篇 Transformer 架构分析文章——然后我意识到,我根本找不到那篇文章了。收藏夹里有,Obsidian 里也剪进去了,但那篇文章写了什么,它和我后来读的三篇相关论文有什么联系,我完全不知道。我只记得”当时觉得很有意思”。
然后 Karpathy 发了一个 GitHub Gist,把这件事说得非常清楚:我的问题不是缺工具,是缺一个能把知识”编译”起来的机制。
RAG 那条路走不通
在 Karpathy 的 Gist 里,他开头就把问题说明白了。当前大多数人用 LLM 处理文档的方式是 RAG——把文件上传,问问题的时候 LLM 去检索相关段落,拼出答案。NotebookLM、ChatGPT 文件上传、大多数向量数据库方案,都是这套逻辑。
他说的那句话我觉得戳到了很多人:”Ask a subtle question that requires synthesizing five documents, and the LLM has to find and piece together the relevant fragments every time. Nothing is built up.”
翻译一下就是:你问了一百次,知识库里的知识还是零。每次查询都是从头开始的一次性劳动。
我对着这句话想了一下自己的 Obsidian。里面塞了两年多的内容,一千多个笔记,但每次我需要综合五篇文章来回答一个问题,我还是要自己翻出来、自己读、自己归纳。工具帮我”存了”,但没帮我”理解过”。
Karpathy 的三层楼
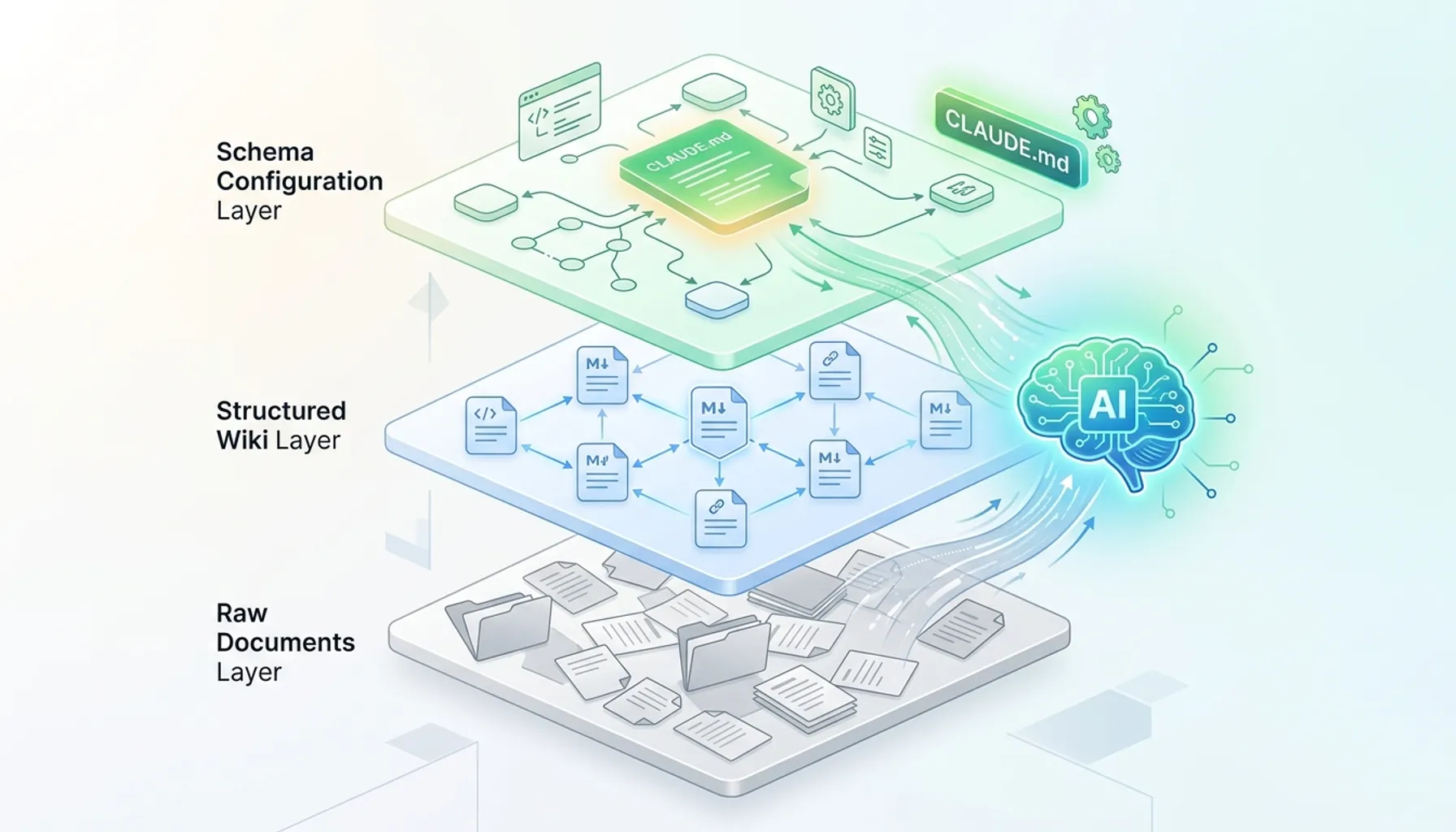
Gist 里提出的架构分三层:
第一层叫 **raw/**,放原始资料。论文、文章、截图——放进来不许改,这是事实的基础,LLM 只读不写。
第二层叫 **wiki/**,是 LLM 生成和维护的结构化 Markdown 文件。每个概念有自己的页面,每个实体(人、项目、论文)有自己的页面,还有综述、对比、索引。你读这层,LLM 写这层。
第三层是 CLAUDE.md 或 AGENTS.md——Karpathy 叫它 “the schema”,中文可以叫模式层。它告诉 LLM 这个 wiki 的规范是什么、收到新资料时应该怎么处理、回答问题时应该走什么流程。Karpathy 自己写道:”it’s what makes the LLM a disciplined wiki maintainer rather than a generic chatbot”。
我第一次读到”模式层”这个概念的时候愣了一下——因为这不就是 superpowers 里 SKILL.md 做的事吗?只不过 superpowers 是约束 Claude 怎么写代码,这里是约束 Claude 怎么管知识。同一种思路,两个不同的战场。
三个操作,换一种理解知识的方式
架构配套三个操作,Karpathy 用的词是 Ingest、Query、Lint,我更喜欢叫:灌入、提问、巡检。
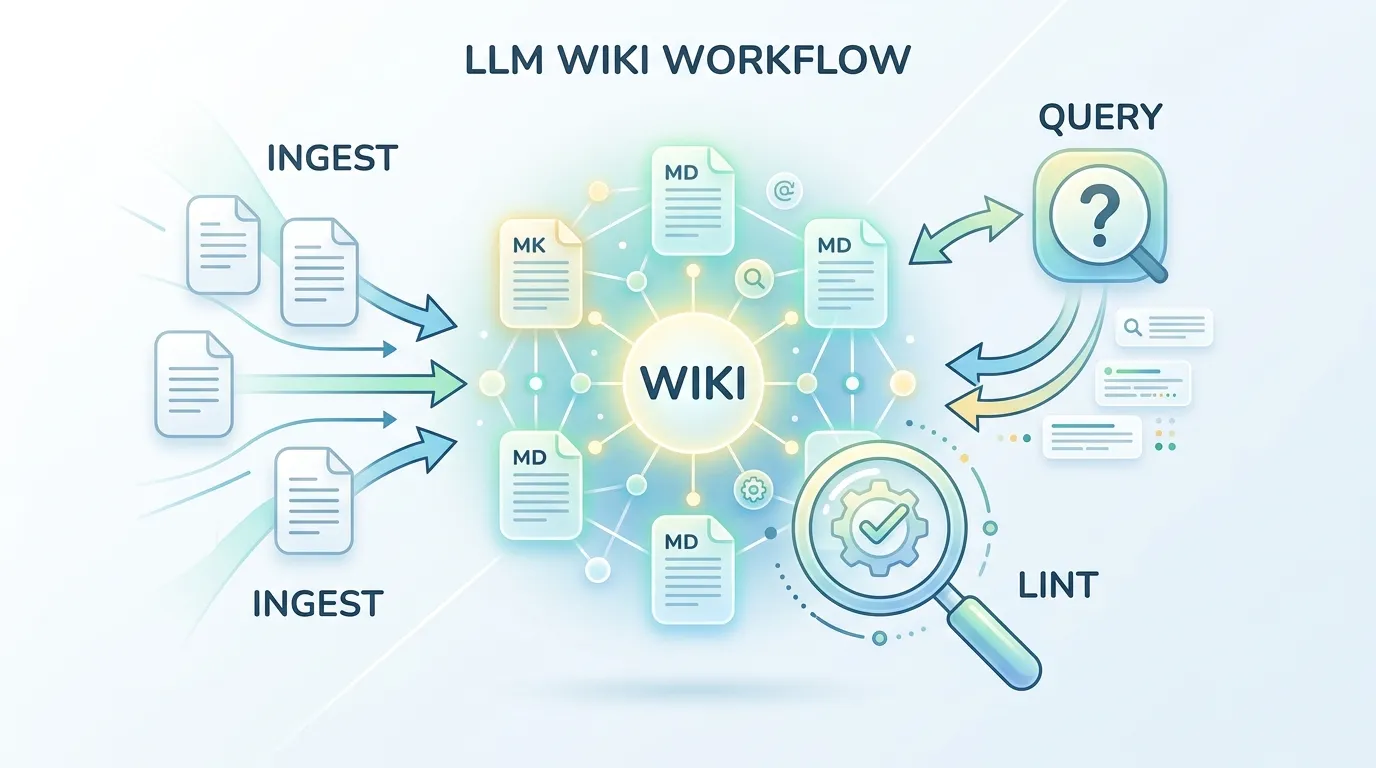
灌入不只是”存进去”。你扔进一篇文章,LLM 读完,和你讨论重点,然后去更新 wiki 里十几个相关页面——“A single source might touch 10-15 wiki pages”。你放进去的不是一个文件,是一次知识融合。第 50 篇文章进来的时候,LLM 能把它和已经整理好的前 49 篇对比,标注矛盾,更新结论。
提问比 RAG 查询多了一步——答案可以存回 wiki。你问”过去三年 attention 机制的主要演进方向”,LLM 综合了二十篇文章给你一个分析,这个分析本身就是有价值的知识,可以直接变成 wiki 里的一个新页面。你的探索行为本身也在喂养知识库。
巡检是我觉得最低估的操作。定期让 LLM 检查整个 wiki:哪些页面互相矛盾了?哪些概念被提到但没有自己的页面?哪些老结论被新资料推翻了但还没更新?Karpathy 叫它 “health-check”,我叫它知识库的坏账清查——你以为自己懂的东西,这个操作会告诉你哪些其实是空的。
他还提到 index.md 和 log.md 两个辅助文件——前者是所有页面的目录加摘要,后者是操作历史的时间线。在约 100 篇资料、40 万字的规模下,靠这两个文件导航就够了,不需要向量数据库。
“Obsidian 是 IDE,LLM 是程序员,wiki 是代码库”
这是 Karpathy 自己说的。我第一次读到这句话的时候想起了另一句话:他在讲代码的时候说过,”大多数程序员用 AI 就是在找更快的复制粘贴”——他觉得真正的改变是让 AI 理解系统的架构,而不只是生成一段代码。
LLM Wiki 对知识的态度一模一样。书签管理器只负责存,这里做的是把存进来的东西真正”读透”——跨文件综合、找矛盾、更新结论。
实际操作里,Karpathy 说他在屏幕一边开着 LLM,另一边开着 Obsidian,实时看 LLM 在 wiki 里做什么改动——“I browse the results in real time — following links, checking the graph view, reading the updated pages.”
我把这个画面想象了一下:LLM 在写,你在读,两个人在协作维护同一份知识。只是其中一个不会累,不会忘,不会因为昨天读了二十篇文章今天就全忘了。
Hermes Agent 把这件事推进了一层
Karpathy 的 Gist 是一个架构思路,不是一个现成系统。NousResearch 的 Hermes Agent 走了另一条线——它想做的是”会自己进化的 agent”。
Hermes 的 GitHub 页面上有一句话:”The only agent with a built-in learning loop.”
它在每次复杂任务完成后会主动给自己创建新的 skill,下次遇到类似任务时 skill 已经在那里了。它还有 FTS5 全文搜索,能跨会话检索自己的历史对话,在每次会话开始时给自己一个”briefing”——类似于 Karpathy wiki 里的 log.md,但针对的是 agent 自身的行为历史而不是外部知识。
两者叠在一起各管一块:Karpathy 的 wiki 管领域知识——你读了什么、这些知识之间什么关系;Hermes 管行为知识——它自己怎么干活、干过什么、总结出了哪些 SOP。wiki 在进化,agent 也在进化,但进化的内容不一样。
VentureBeat 报道里提到有人把这套东西扩展成了 10-agent swarm:Hermes 作为质检员,每一篇 LLM 生成的 wiki 草稿都要过它的关,验证通过才能进”正式版”。叫 “Quality Gate”。这个设计让我想起软件开发里 CI/CD 的 review 流程——知识库的合并请求,也要有人审。只是这里”审稿人”也是 AI。
我现在最想做的一件事
读完 Karpathy 的 Gist,我打开了自己的 Obsidian,数了一下 writing-agent 目录下的文件数量——97 个。
两个月,97 篇原始资料。
里面我真正能说出来”这篇讲了什么、和那篇有什么关系”的,大概 15 篇左右。剩下的,当时觉得有用剪进来,然后进入了一个叫”待整理”的黑洞。
Karpathy 说 “Nothing is built up.”
我对着自己的 Obsidian 愣了一下——我建了一个仓库,里面什么都没有建起来。
我打算这周做一件事:在 Obsidian 里建一个 wiki/ 目录,写一个 CLAUDE.md 把灌入流程定义好,然后把最近两个月读过的文章重新跑一遍 ingest。不是为了把它们都整理完——是为了看第一次 lint 操作会发现什么漏洞,它会指出哪些我以为自己理解了但其实没有理解的地方。
我有点期待那个结果,又有点不敢看。
你有没有试过类似的 LLM Wiki 工作流?跑起来之后第一次 lint 发现了什么?我现在主要是在想这个——那份巡检报告,大概是对”我真正学到了什么”最诚实的一次测试。