Graphify:一条命令,把代码+文档+讨论拉成一张知识图谱
上周接手了一个同事离职留下的项目。Python 后端,三万多行代码,分布在 60 多个文件里。
README 写了半页,最近一次更新是去年 8 月。设计文档在飞书的某个不知道哪层的文件夹里,打开一看,跟现在的代码已经对不上了。Slack 里倒是有一些讨论记录,但散落在三四个频道里,搜半天搜不出完整的决策链。
我花了两天时间,才把核心模块之间的调用关系理清楚。两天。
后来在 GitHub Trending 上刷到了 Graphify,10 天涨了 2 万多星。我以为又是一个 demo 级的项目,随手点进去看了看,结果试了一下就没停下来。
它解决的是一个真实的痛
复杂项目最头疼的地方,往往不在代码本身——代码再烂,花时间总能读懂。真正要命的是知识碎片化。
代码在 GitHub,设计文档在 Notion 或飞书,技术讨论在 Slack 或微信群,架构图在某个 Draw.io 文件里,上次技术评审的录屏不知道存哪了。每种信息用不同的格式存在不同的地方,想搞清楚一个模块为什么这么设计,你得同时打开四五个工具来回跳。
新人接手项目要拼图。就算是自己写的代码,两周不看也要拼图。
Graphify 干的事情说起来很简单:你给它指一个目录,它把里面的代码、文档、PDF、图片、甚至视频全部吃进去,然后吐出一张可交互的知识图谱。代码里的函数调用关系、模块依赖、文档里提到的概念、讨论中出现的设计决策——全部变成图上的节点和边。
我实际跑了一下
先装:
1 | pip install graphifyy |
注意 PyPI 上的包名是 graphifyy,两个 y。
然后对着项目目录跑:
1 | graphify . |
等了大概三分钟(我的项目大概 60 个文件),它生成了三个东西:
graph.html — 一个可以在浏览器里直接打开的交互式图谱。节点可以点击、搜索、按社区过滤。我点了一下核心的 OrderService 节点,它的上下游依赖一目了然:哪些模块在调用它,它又依赖了哪些底层服务。之前我花了半天才理清楚的调用链,图上拖拽几下就看明白了。
graph.json — 持久化的图数据。下次文件改了不用全量重跑,graphify . --update 会用 SHA256 哈希比对,只处理变更的文件。
GRAPH_REPORT.md — 一份纯文本的架构摘要。它会告诉你图里哪些节点是中心节点、哪些模块之间有意想不到的连接、建议你进一步问什么问题。这份报告的定位是给 AI 助手看的——让 Claude 或 Copilot 在帮你写代码之前,先读一遍这个报告,就能拿到项目级的理解。
让我意外的几个点
它不只吃代码。 我试着把之前那份飞书文档导出成 PDF 丢进去,又把 Slack 里的几段关键讨论截图扔进去。Graphify 把 PDF 里的概念提取出来了,截图也通过视觉模型分析了。最后图上出现了”限流策略”这个节点——这个概念只在讨论截图里出现过,代码里没有任何变量叫这个名字,但它确实是整个模块设计的核心约束。
置信标签。 图上的每条边都标了来源:EXTRACTED 表示从代码里直接提取的(比如 import 语句、函数调用),这些是确定的事实;INFERRED 表示模型推断的,附带一个 0 到 1 的置信度分数;AMBIGUOUS 直接标红,提示你这里需要人工确认。
我一开始没在意这个设计。后来发现它帮了大忙——有一条边把 PaymentService 和 NotificationService 连在一起,标的是 INFERRED,置信度 0.4。我看了一下,发现确实有个间接依赖,但不是直接调用,而是通过消息队列。如果没有这个置信标签,我可能直接把它当成事实了。
代码不出本地。 代码解析用的是 Tree-sitter,纯本地 AST 提取,不走网络。只有文档、图片这些需要语义理解的材料才会送到 LLM API。我之前用其他 AI 代码分析工具,最头疼的就是要把整个仓库传上去——公司的私有代码,传一次心里就咯噔一下。Graphify 这个分层设计至少让代码本身不离开机器。
技术上怎么实现的
我好奇它跑的时候到底在干什么,看了一下日志和源码。
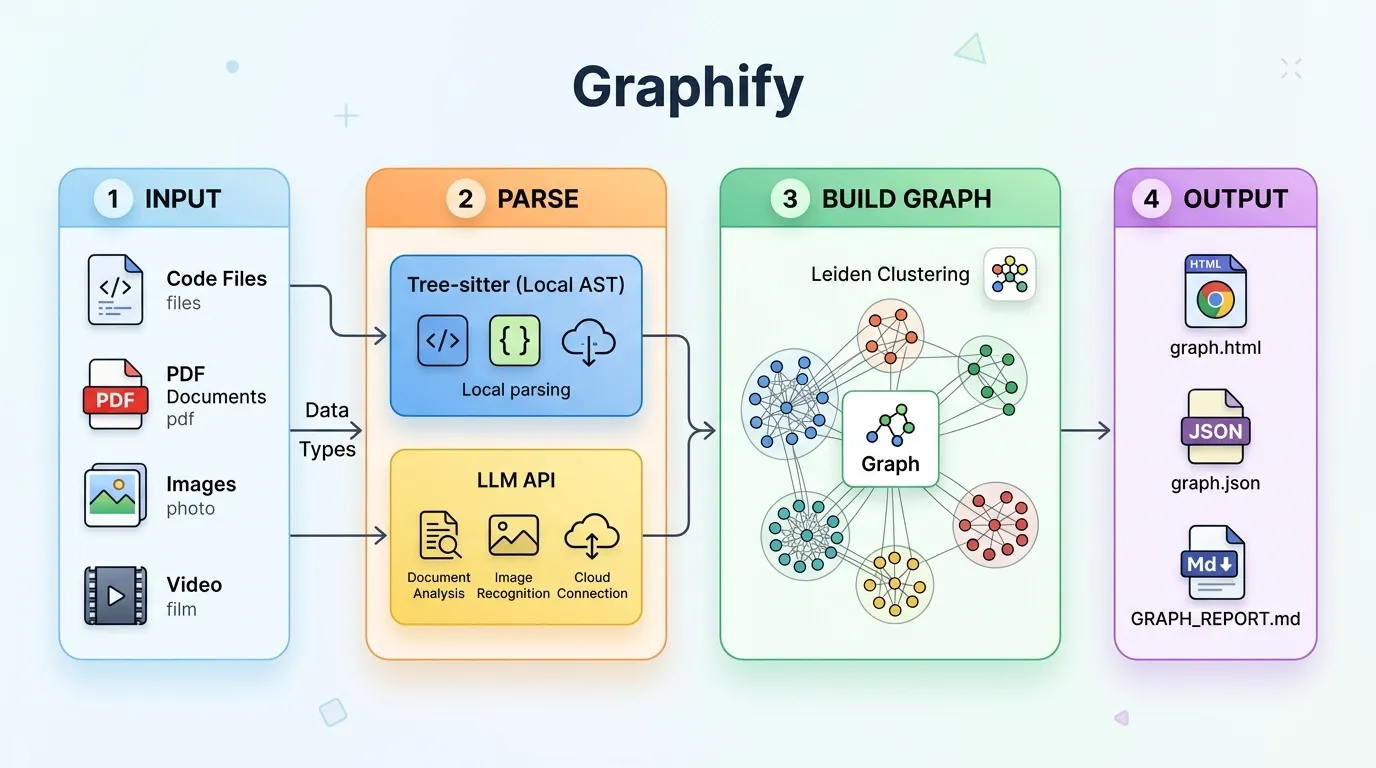
跑起来之后最先动的是 Tree-sitter。它对代码做 AST 解析,支持 23 种语言,Python、Go、Rust、Java 这些都有。提取出来的东西包括类定义、函数签名、import 关系、调用图。整个过程纯本地,不需要任何 API,跑完之后代码层面的关系就已经有了。
如果目录里有视频或音频文件,faster-whisper 会在本地做转录。我没试这一步,不过文档说音频也不出本地。
剩下的文档、PDF、图片、转录文本就得靠 LLM 了。Graphify 会把这些材料送给 Claude 或 GPT-4,让模型提取概念和语义关系。这一步是并行跑的,多个子 agent 同时处理不同文件,所以速度还行。
最后用 NetworkX 把所有结果合成一张图,再用 Leiden 算法做社区检测——简单说就是把关系紧密的节点自动聚成一簇。整个链路不用向量数据库,不用 embedding,纯粹基于图的拓扑结构来分群。
它能接几乎所有 AI 编程工具
Graphify 不只是一个独立工具,它设计成了 AI 编程助手的”知识层”。支持的平台列表有点长:
Claude Code、OpenAI Codex、Cursor、Gemini CLI、GitHub Copilot CLI、Aider、OpenCode……总共 12 个。
装到 Claude Code 里是这样的:
1 | graphify claude install |
它会自动在项目里生成 CLAUDE.md 和一个 PreToolUse hook。之后 Claude 在帮你写代码之前,会先读 GRAPH_REPORT.md 拿到全局理解。官方给的数据是,对大仓库来说,用图谱比直接读源文件省 71.5 倍 token。
我自己实际感受没有那么夸张,但确实有帮助——Claude 不再需要我一个文件一个文件地喂上下文了,它直接从图里知道哪些模块相关。
几个值得一提的功能
增量更新。 文件改了之后跑 graphify . --update,只处理变化的部分。日常开发不需要每次全量重建。
Watch 模式。 graphify . --watch 会监听文件变化,自动同步图谱。适合边开发边看图。
多种导出格式。 除了 HTML 和 JSON,还能导出到 Obsidian vault(--obsidian)、Neo4j(--neo4j)、SVG(--svg)、GraphML(--graphml,Gephi 和 yEd 能直接打开)。
添加外部资源。 可以把论文、视频、网页 URL 加进图里:
1 | graphify add https://arxiv.org/abs/1706.03762 |
查询。 直接在命令行问问题:
1 | graphify query "attention 和 optimizer 之间有什么关系?" |
现阶段的问题
说说不好的。
这个项目 4 月 3 号才创建,到今天刚 10 天。虽然迭代很快(10 天发了 10 个版本),但还是很早期。
我遇到过 GRAPH_REPORT.md 生成出来是空白的情况。Kevin Kinnett 的评测里也提到了同样的问题。
对于中等规模的项目(几十个文件),直接用 IDE 的全局搜索可能比走图谱更快。图谱的优势在大型项目和多人协作场景下更明显。
还有一个现实问题:语义提取那一步要调 LLM API,有成本。文件多的话,跑一次的 API 费用不算便宜。
我的判断
回到开头那个场景——接手同事项目花了两天理调用关系。如果当时有 Graphify,我大概率半小时内就能拿到一张全局依赖图。省不省两天不好说,但至少那种”打开代码不知道从哪看起”的茫然感会少很多。
置信标签是我觉得这个工具最值得借鉴的设计。我之前用过几个知识图谱类工具,生成出来的关系全部是一视同仁的实线,你分不清哪些是铁板钉钉的 import 关系,哪些是模型猜的。Graphify 直接把”我不确定”标出来,用的时候心里有数。
但它确实太新了。10 天的项目,我不会拿它来做任何 critical 的事情。更适合的场景是接手新项目、做架构梳理的时候跑一次,拿到一个粗略的全局视图。等它稳定几个月再说。
如果你手上正好有一个”接手别人代码”的苦差事,装上跑一次试试。三分钟的事,看看那张图能不能帮你少翻几十个文件。