Opus 4.7 发布 12 小时,我跑了 6 小时的实测都在这

大家好,我是飞飞。
昨天晚上 Anthropic 把 Opus 4.7 发出来了。4 月 16 号,模型 ID claude-opus-4-7,价格跟 4.6 一样,$5/$25 每百万 token。
我前一天还写了篇文章说 Opus 4.7 还没发布 Figma 就先跌了 6%。没想到文章发出去一天,模型真的来了。
发布之后我从昨晚跑到今天早上,Claude Code 里连着开了大概 6 个小时。把最近手头在卡的几个活儿——一个反复修不好的并发 bug、一个需要看截图改布局的前端、一个跨四个文件的重构——全部让 4.7 跑了一遍。
该说的都在下面。
先说坏消息:token 涨了
这是 Anthropic 自己在发布公告里承认的:4.7 换了新的 tokenizer,同样的输入,token 数可能会到 4.6 的 1.0 到 1.35 倍。
我不信,拿了一段 800 行的 TypeScript 代码,分别用 4.6 和 4.7 的接口跑了下 count_tokens。
4.6:6,124 token。4.7:7,388 token。涨了 20.6%。
这还没完。因为 4.7 在 xhigh 以上的 effort level 下,会思考得更深,也就意味着输出 token 也比 4.6 同 effort 多。我跑同一个”修复这个测试”的任务,4.6 的 max 大概产出 4k 输出 token,4.7 的 xhigh 就已经到 5.5k 了。
也就是说,同样的活儿,4.7 的单次调用大概比 4.6 贵 25% 到 40%。
看到账单那一下我是有点不爽的。但跑了几轮之后我发现——确实贵得有点道理。
但 Anthropic 今早给所有人白嫖了一轮
我正准备写这段吐槽的时候,刷到 @ClaudeDevs 凌晨 4 点发的一条推。
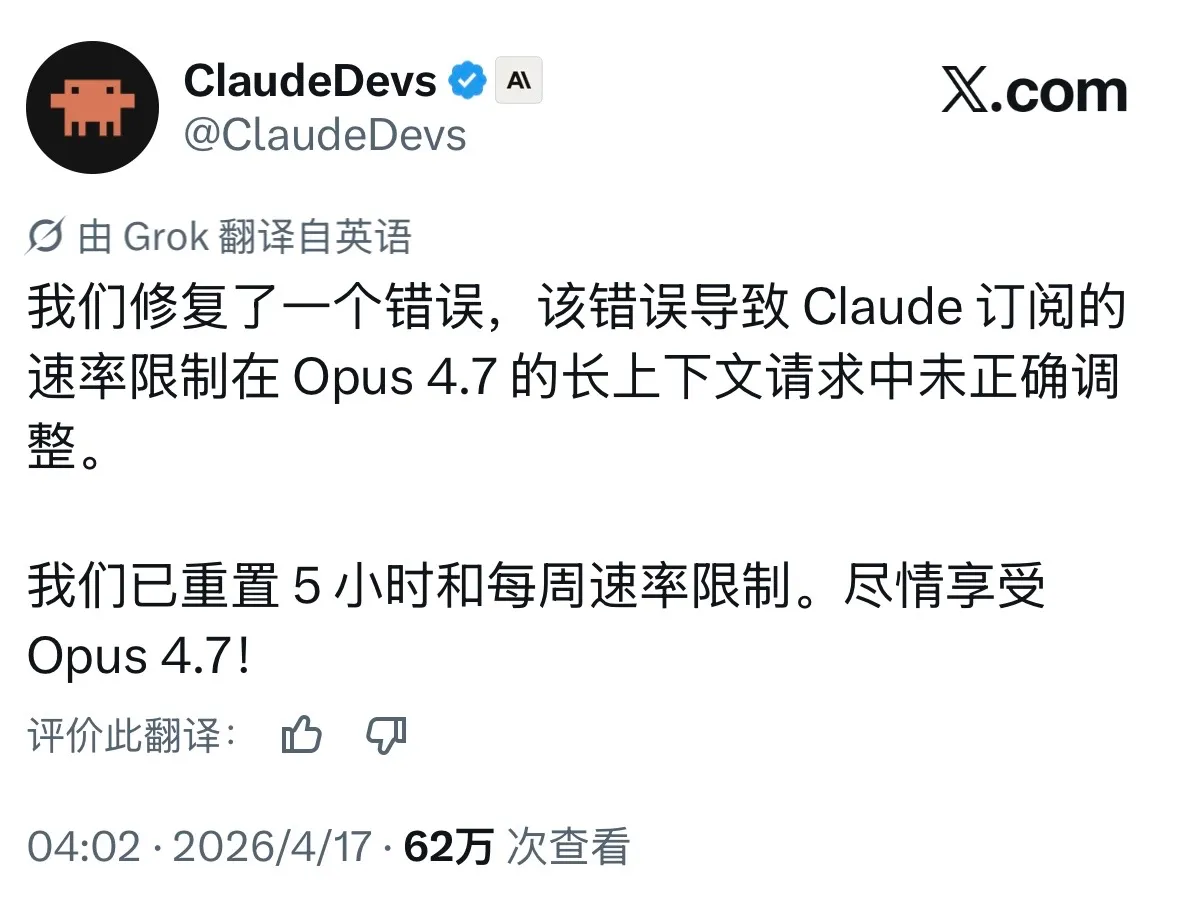
翻译过来是:Opus 4.7 的长上下文请求里有个 bug,订阅用户的速率限制没正确调整。他们修了 bug,顺手把所有人的 5 小时限额和每周限额都重置了一次。
我马上打开 Claude Code 看了一眼:
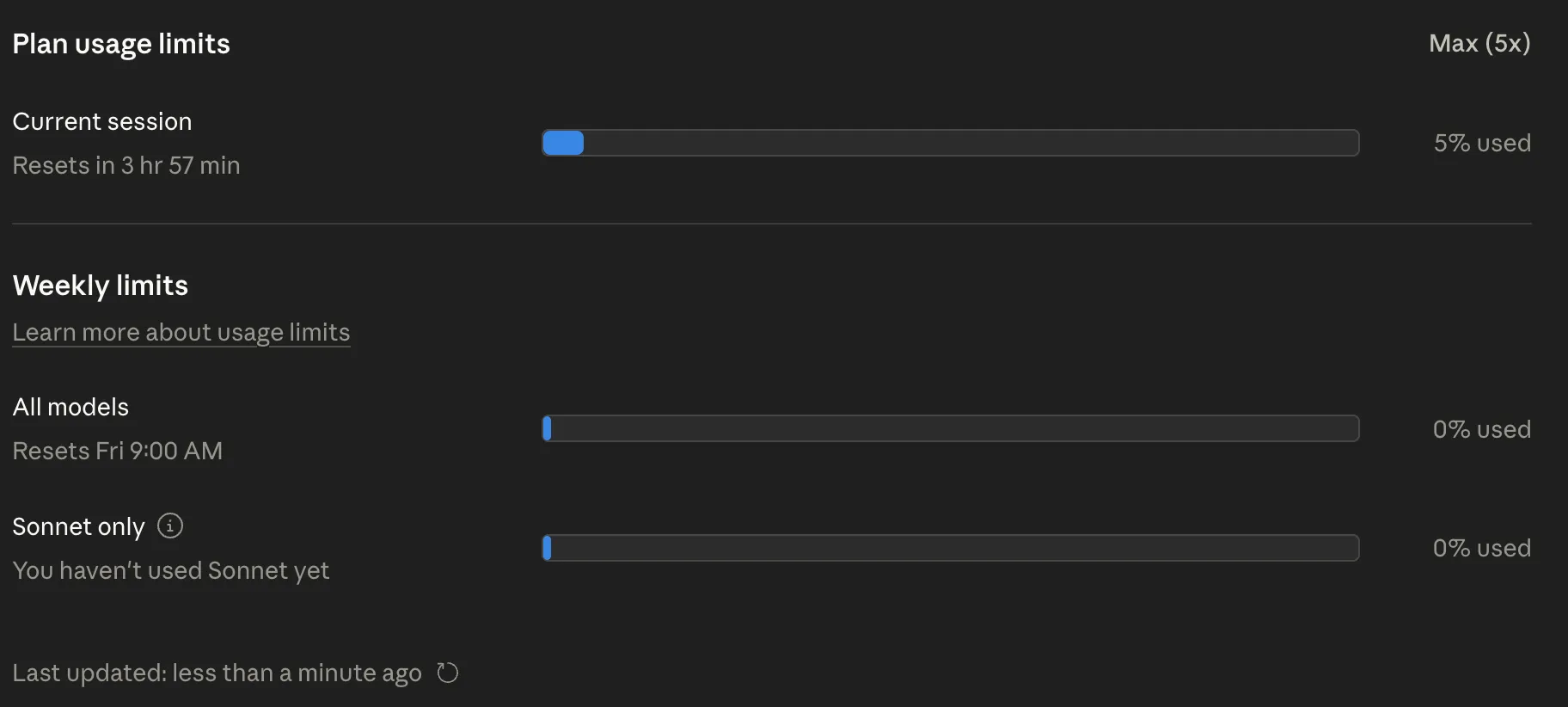
Current session 5% used,Weekly limits 两个槽都是 0%。我昨晚跑了 9 小时,不可能才 5%——这就是清零过的痕迹。
发布当天凌晨发现 bug、4 点修好、顺便给所有人重置限额。这种响应速度的公司,换成别家,我估计得等周一。
算是对 tokenizer 涨价的一点心理补偿吧。
真正让我坐直的是这个 bug
我手上有一个困了两个礼拜的并发 bug。是一个内部的事件分发器,在高并发的时候偶尔会丢事件,但又不稳定复现,本地怎么都跑不出来。
我之前拿 Opus 4.6 改过三次。第一次它给了我一个 lock,跑了两天还是丢。第二次换了个 sync.Map,好了点但还是偶发。第三次它给我加了一层 retry,相当于把问题从”丢事件”变成了”重复事件”。三次都不行,我就放下了,等周末自己啃。
昨晚 4.7 出来我第一反应就是拿这个 bug 试。/model claude-opus-4-7,/effort xhigh,把整个目录加进 context,原始 prompt 跟给 4.6 的一模一样:”找到为什么会丢事件,然后改。”
它跑了 11 分钟。
比 4.6 慢了差不多一倍。但过程里它做了一件 4.6 从来没做过的事——它没有直接改代码,它先写了一个压力测试。一个用 goroutine 跑 10,000 次事件分发、然后统计丢失率的 test。跑起来,本地就复现出来了,丢失率 0.8%。
然后它改代码。改完再跑测试,丢失率 0%。
改完之后它自己翻回去看了一下注释,加了一段解释:问题不在 lock 上,是在 channel 的 buffer 大小和消费者退出时的竞争条件——之前的代码在 consumer 退出前会关掉 channel,但 producer 还在往里塞。
我看了五分钟才反应过来这是什么意思,然后发现它是对的。
4.6 跑了三次没找到的 bug,4.7 跑一次找到了,还顺手写了个可以复现的压测。SWE-bench 涨那 6.8 分,从 80.8 涨到 87.6,看数字好像也就那样。但实际落到我这个 bug 上,就是两个礼拜没合的 PR 今天早上终于合了。
/ultrareview 不是 /review 的升级版
Claude Code 这次多了一个 /ultrareview 命令,Pro 和 Max 用户送 3 次免费体验。
我之前用 /review 审过自己的 PR,通常给我几条建议,有用的大概一半,剩下的是泛泛的”考虑加个日志”、”注意错误处理”。
/ultrareview 体感完全不是一个东西。
我拿了一个 400 行的 diff 跑——一个新加的 OAuth 回调处理。/review 给了我 6 条建议,3 条有用。/ultrareview 跑了 8 分钟,给了我 19 条,分成 critical / high / medium 三级。其中 critical 的 2 条:一个是 state 参数没做 CSRF 验证(我确实忘了),一个是 token 在 log 里打出来了(debug 代码忘删)。
更让我意外的是它读了我的测试文件,指出了一个 edge case 没被覆盖——refresh token 过期后用户第二次点击登录的情况。我测了,确实是 bug。
免费的 3 次我一个早上就用完了。现在在琢磨要不要一直开着。
xhigh 这个新档位是真的有用
Opus 4.7 在 high 和 max 中间加了一档 effort level 叫 xhigh。
之前在 high 和 max 之间总是纠结:high 对某些复杂任务不够用,但 max 又慢又贵,尤其是跑 agent 的时候等半天。
xhigh 的定位就是补这个空档。Claude Code 里现在所有 plan 都默认 xhigh。
我拿一个中等复杂度的重构任务测了三档:
- 4.6 max:87 秒,质量不错
- 4.7 high:45 秒,漏了两个边界 case
- 4.7 xhigh:62 秒,质量对齐 4.6 max
- 4.7 max:124 秒,质量好一点点,但多花了一倍时间
xhigh 确实是那个甜蜜点。Hex 的 CTO 公开说”低强度的 4.7 大约等于中等强度的 4.6”,我自己测下来比较接近的说法是”xhigh 4.7 约等于 max 4.6,但快了 30%”。
只有在涉及全局架构调整、或者跑多 agent 协调的场景下,我才会切 max。
task budgets:Claude 终于知道省着花
这是一个更底层的变化。API 加了一个 task_budget 参数,可以告诉 Claude”这整个任务你最多可以用 XX token”。
跟 max_tokens 不一样。max_tokens 是硬顶——到了就截断,很粗暴。task_budget 是建议——Claude 自己会规划,先花多少在搜文件,剩多少留给修代码,再留多少做验证。
我跑了个长 agent 任务,把 task_budget 设成 50k。它第一步读文件用了 8k,中间搜索和推理 28k,最后验证 11k,总共 47k。没超。
之前跑长任务我都得盯着,生怕它跑飞。现在至少有个护栏。
说白了这功能是给公司买单的人用的——老板设个预算,Claude 自觉省着花。但我一个人写代码的也用得上,跑深夜的后台任务至少不会醒来发现账单炸了。
视觉真的跳了一个档
Opus 4.7 的图片分辨率上限从 768 像素涨到 2,576 像素,面积涨了大概 11 倍。Anthropic 自己的 XBOW 视觉任务分从 54.5% 直接跳到 98.5%。
我试了一下把 Figma 里的一整屏设计稿——真的是一整屏,包含几十个组件的 dashboard——直接截图丢给它,让它看着截图实现。
4.6 时代我得切成 6 张截图分开喂。4.7 一张能吃下,小到组件上的 class 名都看得清。
具体到开发场景:可以把完整的 Grafana 仪表板截图让它分析、可以把设计稿整屏喂进去做前端、可以把 PDF 里的架构图直接读进来。之前做这些都要切图,现在一次性解决。
我还没大规模用这个,但从实测效果看,前端和做数据分析的人应该最爱这个升级。
一个新坑:提示词变”字面”了
这个 Anthropic 没大声讲,但我跑的时候踩了。
4.6 的提示词很宽松。我写”帮我优化一下这个函数”,它会自己判断——优化什么?性能?可读性?错误处理?它会综合判断选一个方向。
4.7 更字面。同样的 prompt 它会反问我:你要哪种优化?给它一个模糊的指令,它就老老实实按字面理解去做,不再”猜”你的意图。
这是好事还是坏事,看角度。对新手可能是坏事——以前模糊 prompt 也能出对活儿,现在必须写清楚。对我来说是好事——以前跑长任务最怕它自己”脑补”走偏,现在它更守规矩。
不过以前那些写得比较随意的 prompt,切到 4.7 之后可能要重新调一遍。我自己的 CLAUDE.md 里有几条就得改得更具体。
到底切不切?
讲这么多,最后还是得回到这个问题。
Cognition 发的说法是”Opus 4.7 可以连贯工作数小时,能啃硬问题”。Factory 测的数据是任务成功率提高 10-15%。CodeRabbit 说它”找的真 bug 更多,可操作反馈更多”。
也顺带把 Anthropic 自己放的对比图甩在这里:
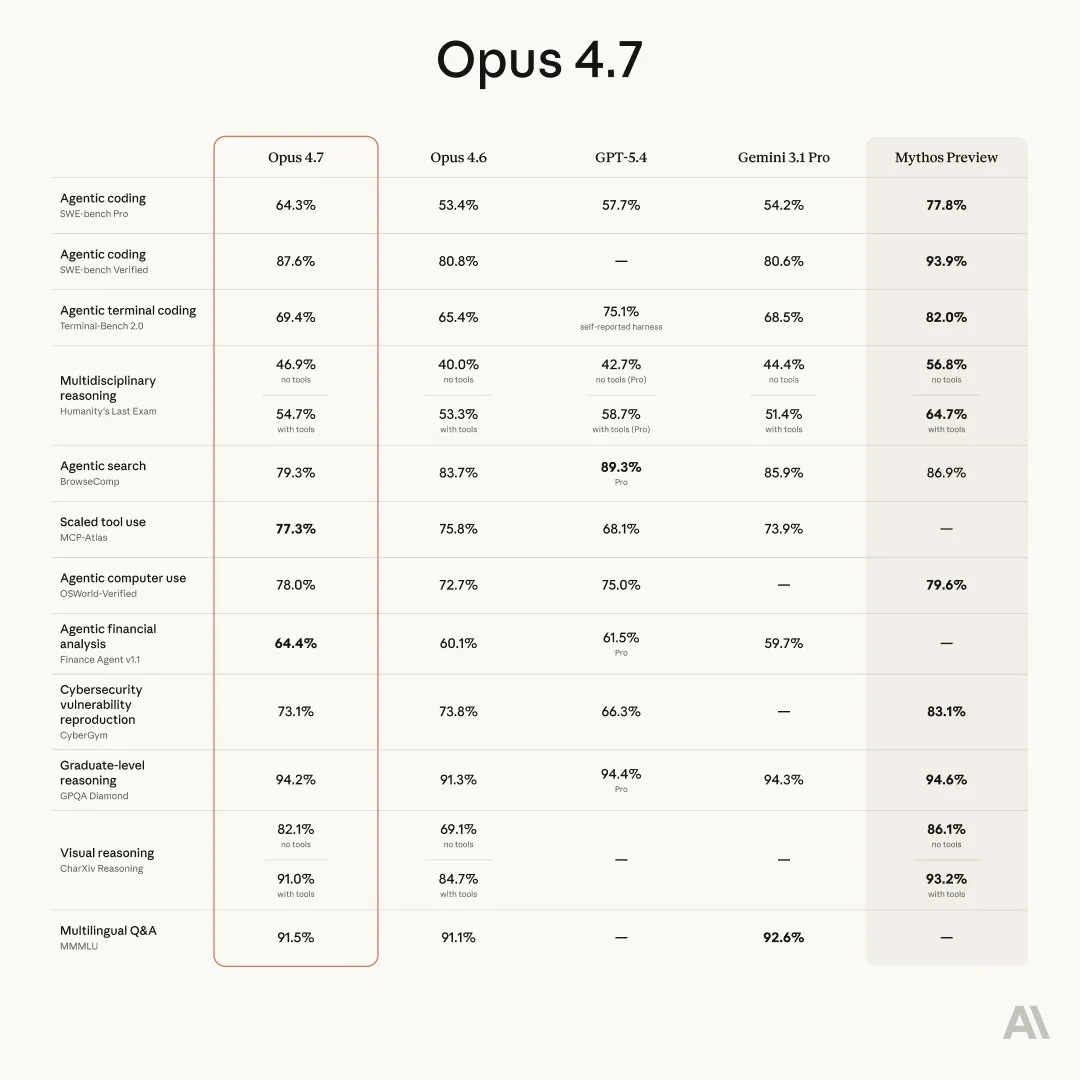
这张表能读出两层意思。第一层是 Opus 4.7 在 agentic coding、MCP 工具调用、财务分析这几个纵列上确实领先——SWE-bench Pro 64.3 比 GPT-5.4 的 57.7 高出快 7 分。第二层比较诚实的是 Mythos Preview 那一列——基本上每个维度都还更高,只是你暂时用不到。Anthropic 这次没藏着掖着,直接把差距写在公告里。
这些都是 early-access 伙伴的话加官方数据,听听就好。但我跑了 6 小时之后的结论是:
如果你每天在 Claude Code 里跑长任务、跑多文件重构、跑 agent 工作流,切。6.8 分 SWE-bench、10% 任务成功率,单看数字都不够亮,但累积起来就是”少修一个 bug、少回一次来”的差别。
如果你只是偶尔用一下做做 chat、问问代码,Sonnet 4.6 够了,便宜五倍。Opus 4.7 的钱花在”跑 2 小时不跑偏”这件事上,你不跑长任务就享受不到。
如果你在 Claude 的价格政策上卡预算了——那个新 tokenizer 让同样的工作贵 25%-40%,加上 xhigh 是默认,账单肯定会涨。Anthropic 给了 task budgets 这个工具,但你得自己学着用。
昨晚 10 点那会儿,我手里还攥着那个修不好的并发 bug。今天早上 9 点发现它已经躺在 merged PR 里了。这种感觉是写过代码的人才懂的——不是技术的飞跃,是某个具体的麻烦终于被摘掉的松弛感。
发布公告里 Anthropic 把 Opus 4.7 定位为”直接升级 4.6”。但我这一天跑下来的感觉,是 Opus 4.6 那种”能用但偶尔掉链子”的状态终于补齐了——至少在我关心的那几个场景里。
你切了吗?跑什么活儿的时候觉得最明显?评论区聊聊。