DeepSeek 悄悄上线专家模式:V4 前夜的最后一块铺垫

大家好,我是飞飞。
4 月 8 号凌晨,我本来在改稿子,顺手打开 DeepSeek 问一个文案问题。输入框上方多了两个图标——一个闪电,一个钻石。鼠标悬停过去,一个写「适合日常对话,即时响应」,另一个写「擅长复杂问题,高峰需等待」。
没有发布会,没有 blog,连一条官方推文都没有。DeepSeek 就这么把快速模式和专家模式推上来了。
今天已经是 4 月 17 号,这 9 天里我把这两个模式当作日常主力用了一遍,也翻了智东西、爱范儿、Reddit 的实测,加上梁文锋内部披露的 V4 时间线。这篇把我盯下来的东西一次讲完。
先看这两个模式到底在差什么
快速模式是闪电图标,日常对话、响应即时,支持图片和文件里的文字识别——本质还是 OCR 拼文本,不是真的看图。
专家模式是钻石图标,擅长复杂问题,高峰需要排队等。现在这个模式反而更”简陋”一点——不支持文件上传,没有多模态,连上传按钮都直接隐藏了。
两个模式的后台有两个共同点:知识库都截止到 2025 年 5 月,上下文窗口都是 1M tokens。
看到这儿我还没反应过来:为什么更强的模式,功能反而更少?
答案其实藏在 Teortaxes(一个一直盯 DeepSeek 技术路线的 KOL)的评论里。他说文件上传限制是暂时的,DeepSeek 在整合系统,为的是之后让用户为更强的专家模式付费。
也就是说,这次上线的不是两个模式,是一套分层入口。强的那个现在先”裸奔”,等多模态、文件上传全部补齐,就是一个成熟的付费位。
我拿 Three.js 跑了一遍
我最常用来测模型代码能力的 prompt 是”用 Three.js 写一个帝国大厦”。不算难,但很看细节——窗户、天线、底座的比例,光照要不要写,材质怎么选。
智东西也跑了这个 case。三路对比下来——专家模式、快速模式、通过 API 调的 V3.2——专家模式的回答速度反而比快速模式还快,在快速模式还没收尾之前,专家模式已经把完整效果交付了。V3.2 最惨,打出来的网页直接黑屏。
我自己在这 9 天里跑了四五个类似的任务,感受跟智东西一致:
简单题目,两个模式差不多。到了物理仿真、Three.js 这种需要跨多个概念缝合的任务,专家模式的优势就明显起来。
爱范儿测了一个更狠的——用 p5.js 写一个小球在旋转六边形里弹跳,带重力和摩擦。这种题目比一般编程更吃数学推理,弱一点的模型会给你一个”看起来像物理但其实不对”的结果。专家模式的落点更准,弹跳轨迹更像样。
输出速度这件事我盯了好几次。专家模式的 token 吞吐比 V3.2 API 快了一个档,这个感受在写长代码的时候最明显——我喂一个 400 行的重构任务,它 80 秒就跑完了,中间甚至不用点”继续”。
但专家模式不是万能的
也是在翻网友测评的时候,我看到一个让我乐了的翻车案例。
有人问专家模式:城门高 4 米,宽 3 米,现在有一根 5.5 米的长竹竿,能不能通过城门?
专家模式答:不能通过。
千问答:平着拿可以,斜着拿也可以。
这是个小学几何题,三维空间里这根竹竿想怎么过怎么过。专家模式把它当成二维平面问题处理了。
有开发者在 Reddit 上也反馈过类似的问题:编程任务上专家模式的错误率反而比快速模式更高,代码完成度参差不齐。
这件事我反过来想了一下——专家模式要真是 V4 正式版,不会翻这种车。所以现在能用到的专家模式,大概率还是 V4 Lite 的某个灰度版本,距离完整版 V4 还有一段距离。
爱范儿那篇里也有一句话说得很实在——“这次灰度上线的专家模式,未必就是最终形态”。
V4 真正的发布窗口
这就引出最重要的一条信息。
4 月 10 号,Sina、Zhitong Finance 等多家媒体援引知情人士,DeepSeek 创始人梁文锋在内部沟通里明确了:V4 将在 4 月下旬正式发布。
V4 之前原定春节档,后来推迟过两次,理由是”更深度的国产芯片适配”和”架构细节优化”。这次内部锁定时间,基本确认跳票到此为止。
我做了一张时间线能看得更清楚:
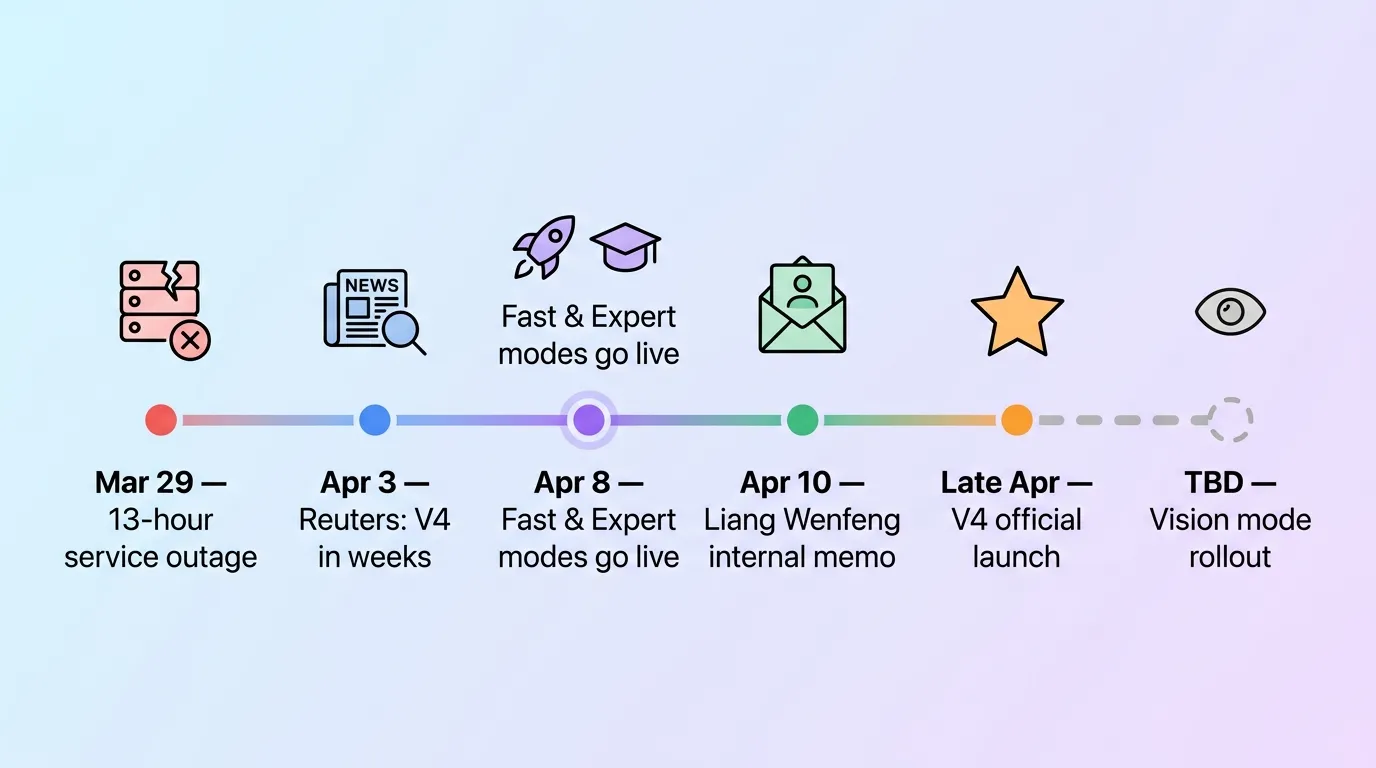
- 3 月 29 日:DeepSeek 出现 13 小时服务中断,开发者圈猜测是 V4 测试部署
- 4 月 3 日:Reuters 引 The Information 报道 V4 将在”几周内”发布
- 4 月 8 日:快速/专家模式灰度上线
- 4 月 10 日:梁文锋内部披露 4 月下旬发布
- 4 月下旬:V4 正式版预计上线
- 未定:视觉模式开闸(前端代码里已经抓到)
这个节奏连起来看,是一个很完整的灰度铺垫——先让用户感知分层,再让他们感知能力差异,最后视觉模式开闸,一套全新的产品矩阵就成型了。
V4 的规格和它真正要做的事
V4 的规格流出来的已经不少:
1T(1 万亿)总参数的 MoE 架构,但每次推理只激活 32 到 37B 参数——这是 DeepSeek 从 V3 就沿用的做法,参数规模看着吓人,推理成本其实还比较克制。
百万级上下文窗口,知识库截至 2025 年 5 月,Apache 2.0 开源许可。
但真正让我觉得这次 V4 的意义跟以前不一样的,是另一条不那么显眼的信息——V4 将首次深度适配华为昇腾等国产芯片。
这句话放在公告里可能就是一行,但背后的事是:这会是第一个真正”不需要 NVIDIA 的前沿模型”。
所有其他的前沿模型——GPT-5、Claude、Gemini——底下跑的都是英伟达。V4 如果真能在华为昇腾上把训练和推理完整跑通,意味着国产算力第一次被一个前沿模型当作主场,而不是替代方案。
阿里、字节、腾讯已经预订了几十万颗国产算力芯片,等 V4 一出就上云服务。这些芯片订单动辄六位数起,下单的时间点都卡在 V4 发布前的几周里——厂商赌的就是 V4 出来之后用户端的涌入。
反商业神话即将破灭
我一直挺喜欢 DeepSeek 过去这一年的风格——API 便宜到离谱,网页端完全免费,没有付费墙,没有分层。去年一月那波全球 AI 圈的震动,很大一部分情绪来源是:”原来东西可以这么便宜还这么强。”
但这个模式显然不可持续。
幻方量化再能赚钱,也填不完一个全球级 AI 服务无限期免费运营的窟窿。每个月的 GPU 推理账单、服务器电费,都是实打实的钱。
现在把”更强的模型”和”更基础的模型”做成两个入口,分层架构一搭好,付费墙加不加只是时间问题。
专家模式现在还是免费的。但当 V4 正式版上线、视觉模式开闸、文件上传在专家模式下被补齐——一个完整的付费位就成型了。
“普惠 AI”这个标签 DeepSeek 应该还会继续挂着,但下面挂的价目表可能会变得不太一样。
那我现在切不切?
讲到这里其实问题已经很清楚了。
平时只用 DeepSeek 问问题、查资料、写点日常文案的话,快速模式完全够,切到专家模式反而还得排队。
写代码、做物理仿真、跑复杂推理,专家模式是当前免费段位里最值得切的——我这 9 天跑下来,它不一定每次都比 Claude Opus 4.7 强,但价格上跟 Opus 4.7 完全不是一个数量级。
至于在等 V4 正式版的人——把这 9 天当成一个免费试驾。梁文锋把发布时间锁在 4 月下旬,大概率就是这周或者下周。
4 月 8 号凌晨我打开 DeepSeek 的时候,本来是想问一个改稿的小问题。那两个图标跳出来的时候我盯着看了几秒——闪电和钻石。当时觉得就是 UI 换了样式。过了 9 天我才慢慢反应过来,这家一直被贴着”反商业”标签的公司,开始讨论”分层”这件事了。
你有没有切过专家模式?跑什么任务的时候觉得差异最明显?评论区聊聊。