Anthropic 内测的 Insights 功能里,藏着一份值得抄的 LLM 反幻觉 spec
大家好,我是飞飞。
今天有人在群里转了一段 Anthropic 内测中的 Insights 功能的工程 spec 给我。Insights 是 Anthropic 给 Claude Console 上的 Managed Agents 用户做的”跨 session 分析”工具,目前还在测试阶段,主流媒体没正式覆盖。
但我读完那段 spec 之后觉得它比 5 月 6 日 Code with Claude 大会上发布的那几个旗舰功能(Dreaming、Outcomes、Multiagent Orchestration)都更值得写一篇。
理由:这是我最近半年看到的 LLM 应用层最干净的一份”反幻觉架构”spec。普通开发者写自己的 LLM 应用如果遇到”跨数据点做 cross-record 分析”这类需求,几乎可以照着这套架构抄。
下面把这段 spec 拆开讲,重点不在新闻本身,在它的设计哲学。
先把 Insights 这个功能的机制描完
把用户给我的那段 spec 翻译成中文摆出来,再讲解读。
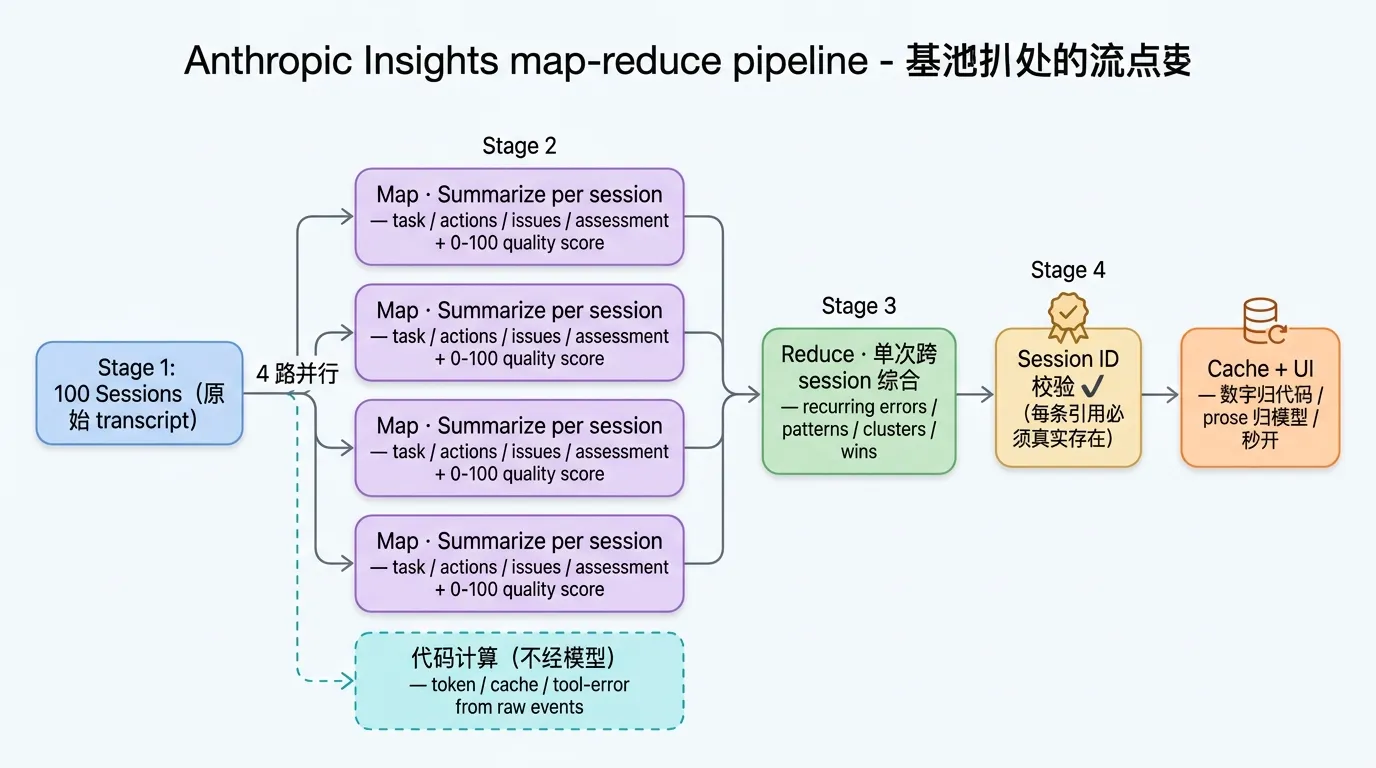
整个流程从抓 session 开始。Anthropic 抓你这个 Managed Agent 最近最多 100 个 session。
抓完之后进入并行 summarize。每条 transcript 单独发给模型(4 路并行),上下文里带上你这个 agent 的 system prompt。模型为每个 session 写一份 summary,字段包括 task(这个 session 在干啥)、actions(agent 做了哪些动作)、issues(有什么问题)、assessment(整体评价)。再额外打一个 0 到 100 的 quality score。
跟 summarize 同步进行的是硬数据计算。token 消耗、cache 命中、tool 调用错误数这些数字不让模型算,而是直接从原始事件流里数。
所有 summary 和硬数据备齐之后,做单次跨 session 综合。把它们一起塞给模型,模型做一次跨 session 调用,产出几类输出:
- recurring errors(反复出现的错误)
- usage patterns(使用模式)
- efficiency outliers(效率异常的 session)
- wins(做得特别好的 session)
- error category buckets(错误归类桶)
- use-case clusters(场景聚类)
每个被引用的 session ID 都要和输入对照过校验,模型说的”参考 session #abc”必须真实存在于输入列表里。
最后两件事是工程层的兜底。summary 和 finding 都缓存存盘,下次刷新页面直接秒开。数字归数字、文字归文字:用户在 UI 上看到的所有数字(counts、percentages、per-cluster token 统计)都从原始事件流算的;模型只负责写文字描述(prose)和决定”这个 session 应该归到哪个 bucket”(bucket membership)。
简单一句话总结这套架构:LLM 只做语言任务和分类任务,所有数字 / 引用 / 真实性校验由代码兜底。
这套设计里的 4 个关键反幻觉决策
读完上面那段,最值得抄的是 4 个具体决策。
把 token 数和错误数从事件流直接算,模型不碰
这是最反 LLM 第一反应的设计。
按”自然”做法,我们会让模型在 summarize 的时候顺手输出”这个 session 用了多少 token、出了几次 tool error”。模型见过这些数字,写一个数出来好像没问题。
但 LLM 数数是出名的不靠谱。10 万 token 的 session 让它告诉你具体消耗了多少 token,它会给你一个看起来合理但和真实事件流对不上的数字。
Anthropic 把数数这件事完全从模型职责里拿掉,让代码从原始事件流里数。模型只负责描述发生了什么,不负责数发生了多少次。
抄走原则:你自己的 LLM 应用里,凡是有”具体数值需要从原始数据计算出来”的地方,全部用代码算,不让模型碰。模型只输出 prose 和 categorical 字段。
4 路并行 summarize + 1 次综合调用,经典 map-reduce
100 个 session 不能直接塞进一次模型调用。哪怕模型 context 够大,做 100 个 session 的 cross-correlation 也会让模型质量崩。
Anthropic 选了经典的 map-reduce 架构:100 路 → 4 路并行(每路 summarize)→ 1 路综合(cross-session findings)。
这个设计巧的点在于,summarize 阶段是平行任务(每个 session 互不影响),综合阶段是串行任务(需要看全所有 summary 找 pattern)。这两个阶段对模型能力的要求不一样:summarize 要可靠+便宜,综合要 reasoning 强+一次能装下 100 份 summary。
理论上 summarize 可以用更便宜的小模型(Sonnet 或 Haiku),综合用 Opus。spec 里没明说但架构允许这种 cost optimization。
抄走原则:跨数据点的 LLM 任务尽量拆成 map(每条独立处理)+ reduce(一次综合)。map 阶段并行 + 用便宜模型;reduce 阶段串行 + 用强模型。
每个被引用的 session ID 都要和输入校验
这是我最喜欢的一条。
模型在 cross-session findings 阶段会引用具体的 session ID 来举证:”以下三个 session 出现了相同的错误模式:#abc、#def、#ghi”。
但模型可能幻觉出一个不存在的 session ID(特别是当真实 ID 是 hash 字符串那种没有语义的 ID 时)。
Anthropic 的解法是:每个被引用的 session ID 都和输入列表对照校验,对不上的引用直接扔掉或重生成。
这一条解决了 LLM 应用最常见的”言之凿凿但来源是假的”问题。在 RAG、引用生成、cross-document 分析这类场景里,没有 ID 校验环节就等于让模型凭空捏造来源。
抄走原则:但凡 LLM 输出里包含”引用 X”的字段,都要在输出后做校验:X 必须存在于输入里。校验不通过的就拒绝接受,让模型重生成或者直接砍掉那条 finding。
Summary 和 finding 都缓存,模型部分贵代码部分便宜
这条不是”反幻觉”而是”反成本 + 反延迟”,但和反幻觉是配套的。
如果每次用户打开 Insights 页面都重新跑一遍 100 个 session 的 summarize + 综合,单次成本会很高(按 100 个 session × 平均 transcript 长度算,光 input 就是几百万 token),延迟也会到分钟级。
Anthropic 把 summary + finding 都缓存。下次打开页面直接读缓存。
更妙的一点:因为数字不是模型算的而是代码从事件流算的,数字部分可以单独刷新而不重跑 summarize。这意味着用户看到的 token 消耗、percentage 等数据可以是”昨天的 prose 解读 + 今天的硬数据”。
抄走原则:LLM 输出里”模型算的部分”和”代码算的部分”要分开存、分开刷新。代码算的便宜+实时,模型算的贵+缓存复用。
把 Insights 放进 5/6 大会的全景里
5 月 6 日 Anthropic 在 Code with Claude 大会上发了 Dreaming、Outcomes、Multiagent Orchestration 三个面向 Managed Agents 的功能。Dreaming 也是抓最多 100 个 past session 找 pattern。
那 Insights 和 Dreaming 什么关系?
我现在的判断(基于 spec + 公开报道交叉对比):
Dreaming 是给 agent 自己用的。它跑完之后产出一份新的 memory store,以后这个 agent 跑新任务的时候会带着这份 memory 去做。
Insights 是给开发者用的。它跑完之后展示一份分析仪表板,给开发者看 agent 表现得怎么样、哪里反复犯错、哪些 session 最高效。
这两个东西底层基础设施可能共享(都是 100 session、都做 cross-session pattern mining),但产品定位不同。Dreaming 让 agent 改进自己,Insights 让开发者改进 agent 的设计(system prompt、tools、skills 配置)。
放在一起看,这是 Anthropic 在 Managed Agents 这个产品上做”双向反馈环”:agent 通过 Dreaming 自我改进,开发者通过 Insights 看到改进的方向。两条线一起上,agent 才会真正变得”越用越好”。
而且仔细看 Insights 的 spec,它的输出明显是要喂回到 Outcomes 和 Multiagent Orchestration 那两个工具里的:
- “recurring errors” → 直接进 Outcomes 的 rubric,做 retry 逻辑
- “use-case clusters” → 决定 Multiagent Orchestration 里哪些 sub-agent 要拆出去
- “efficiency outliers” → 提示开发者哪些 session 应该被研究
所以 Insights 不能只看成孤立功能。它在 Anthropic Managed Agents 这一整套自我改进基础设施里扮演的是”分析层”。
对自己写 LLM 应用的开发者意味着什么
我自己虽然不在 Managed Agents 上写复杂 agent 系统,但有几个工作流可以直接抄这套设计。
我有一个 content-polisher skill,每次跑都会输出一份”AI 味检测结果”。如果我把过去 30 天的 polisher 结果拿来做 cross-session 分析,应该可以看出我的写作里反复出现的 AI 味模式(顽固的”不是 X 是 Y”、循环出现的破折号问题等)。
如果按 Insights 这套架构抄,我会这么做:
每次 polisher 跑完留下原始 event log(不只是最终评分)。这是事件流。
跑跨 session 分析时,先用便宜模型(Haiku)map 阶段把每篇文章的检测结果总结成 200 字以内的 summary。
reduce 阶段用 Sonnet 或 Opus 做一次综合,输出”反复出现的 3 类 AI 味模式 + 每篇文章引用 ID + 数字部分单独算”。
所有引用的文章 ID 必须和真实 ID 列表校验。
结果缓存,下次只跑增量(只 summarize 新增文章)。
如果跑得通,这个东西可以直接接到 content-training skill 里,让它自动生成新的 WRITING_LESSONS 条目。
这是我打算下周空了试试的具体应用。
还没确认的几件事
最后几个我没确认但值得继续追的点。
Insights 是不是已经向部分用户开放了?我看到的 spec 是内部细节文档,公开报道里没找到 launch 公告。Dreaming 已经是 research preview,Insights 可能是更早期的内部 alpha。
这个功能的定价模式还不清楚。100 个 session 的 transcript 加起来 token 量很大,如果按标准 API 价计费,跑一次成本可能在 $5 到 $20 之间。Anthropic 会不会把这个成本打包进 Managed Agents 订阅里,还是单独计费?
Insights 输出的 finding 能否反向喂回到 agent 的 system prompt 里?如果可以,那就是真正的闭环:开发者看 finding → 改 system prompt → agent 行为变化 → 下一轮 Insights 看出改进了没。这个闭环成立的话,Managed Agents 的产品形态会比现在这套已有的明显进一步。
评论区想问两件事。
如果你也在 Managed Agents 上跑 agent,你已经能看到 Insights 这个 tab 了吗?UI 长什么样?欢迎截图。
另外,你自己写 LLM 应用的时候有没有用过类似的”数字归代码、prose 归模型”分工?我想听具体的案例和坑。