我装了 26 个 Claude Code skill,今天才发现其中 22 个的描述从未真正被加载

大家好,我是飞飞。
今早起来打开 Claude Code,启动栏蹦出来一行黄色 warning:
1 | Skill listing will be truncated |
我第一反应是又出 bug 了。第二反应是我装了多少个 skill。
跑 ls ~/.claude/skills/ 加上项目里的 .claude/skills/,结果是 26 个。其中 22 个的 description 默认就没被加载到 Claude 看得到的列表里。
也就是说我以为自己装了 26 个工具的 Claude Code,实际上 Claude 一启动只看到完整描述的是其中 4 个,剩下 22 个连”它能干什么”这件事 Claude 都不知道。
跑 /doctor 看完之后我意识到这是一个很多人不知道但每天都在影响实际效果的细节。这篇把它讲清楚。
这条 warning 到底在说什么
先把机制摆出来。
Claude Code 在 2.1.129 这个版本之后改了 skill listing 的策略。
更早的版本(2.1.86)是按字符数硬截:每个 skill 的 description 字段最多保留前 250 字符,多的部分丢掉。2.1.105 把这个限制抬到 1,536 字符。这个机制的问题是:作者把重要的 trigger 关键词写在 description 后半段,这部分会被默默丢掉,作者完全不知道。
2.1.129 换了思路。不再按字符数截,而是按 context 总占比限。Claude Code 在 settings.json 里加了一个字段 skillListingBudgetFraction,默认值 1%。
这个 1% 是相对总 context 而言的预算上限。Claude Code 启动时把所有 skill 的 description 加起来算总长度,如果占总 context 超过 1%,就启动一个”丢弃机制”:保留最常用的几个的完整 description,剩下的 skill 只保留名字,description 直接丢掉。
我那条 warning 上的 1.8%/1% 就是说:我所有 skill 的 description 加起来占了 1.8% 的 context,超出 1% 预算 0.8 个百分点,于是触发丢弃,丢了 22 个 skill 的描述。
被丢掉的 skill 不是不能用,名字还在 Claude 看得到的列表里。但 Claude 看不到它们的 description,所以不知道这些 skill 是干什么的、什么场景应该触发它们。结果就是这些 skill 几乎不会被自动唤起,除非你在 prompt 里显式说”用 xlsx skill 处理这个文件”。
跑 /doctor 看具体哪些被丢了
/doctor 是 Claude Code 自带的诊断命令,按官方 troubleshooting 文档的描述,它一次性检查 installation、settings、MCP 配置、context usage 这几件事。
跑 /doctor 之后,输出里会专门有一个 Skills 区块,告诉你:
- 总共找到几个 skill
- 每个 skill 的 description 字符数
- 哪些 skill 的 description 因为 budget 限制被丢了
- 给出建议(跑 /skills 还是抬高 fraction)
我自己跑下来的实际数据:
1 | 项目级(MyHexoBlog/.claude/skills/):8 个 |
26 个里被丢了 22 个。意味着 Claude 启动时只看得到 4 个 skill 的完整 description(根据 warning 提示是”most-used skills”,所以应该是我最近用得最多的几个 content-* skill)。
剩下 22 个的 description 全没了。其中包括我经常会用到的 obsidian-cli(写作流水线里几乎每篇文章都用到)、git-commit(这个最高频)、frontend-design(偶尔用)、pdf、xlsx 这些。
GitHub 上 Issue #56448 里有人报告 2.1.129 升级之后 dropped count 跳到 47,但 2.1.128 是 0。Anthropic 还在调这套机制,不一定每个版本都精确。
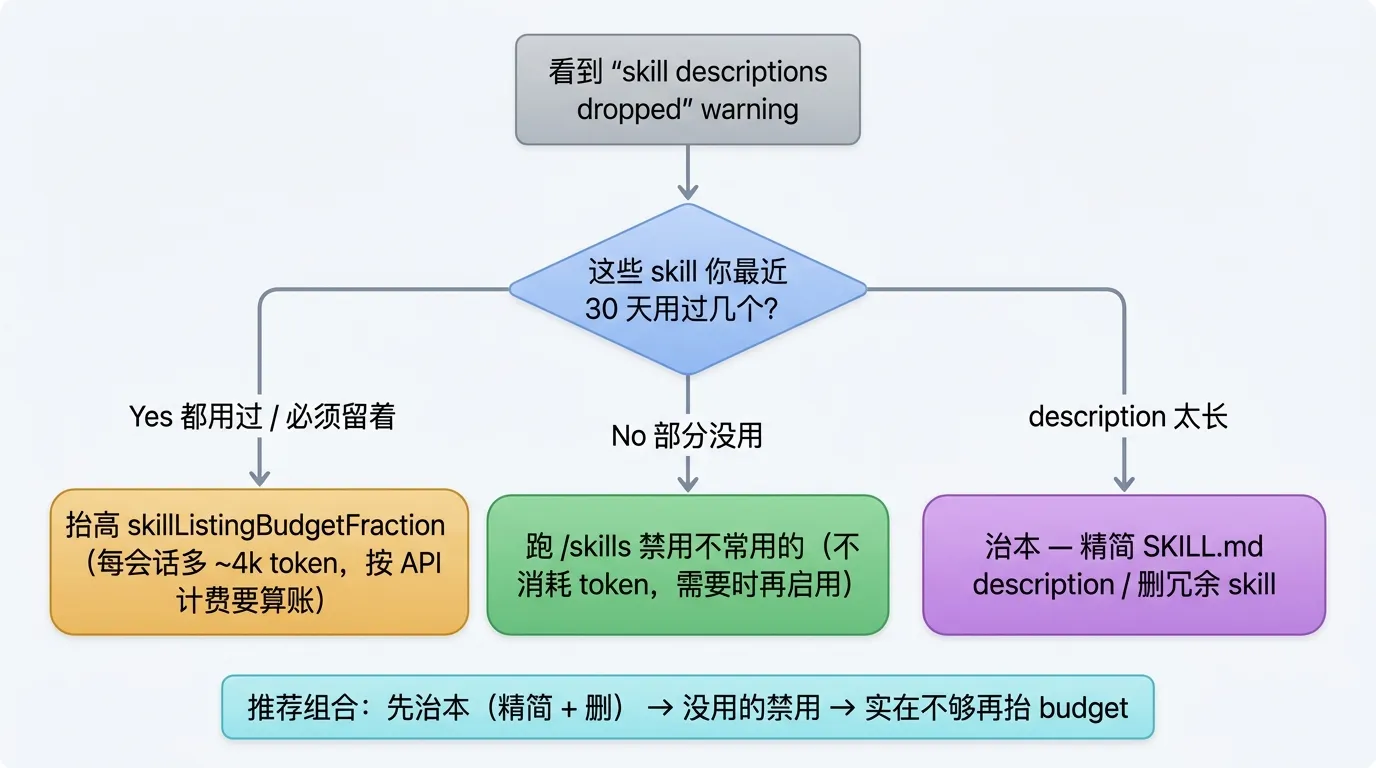
三条处理路径
收到这条 warning 之后有 3 个选择,每个 trade-off 不一样。
第一条:跑 /skills 命令禁用一些不常用的 skill。这是 warning 上推荐的做法。/skills 可以让你交互式选择哪些 skill 启用、哪些禁用。被禁用的 skill 完全不进 listing,自然不占 budget。这条路的好处是不增加 token 消耗。坏处是被禁用的 skill 你显式调也调不到,必须重新启用。
**第二条:抬高 skillListingBudgetFraction**。在 ~/.claude/settings.json 里加:
1 | { |
把 1% 抬到 2%。所有 description 都会被加载。代价 warning 写得很直白:每个会话多消耗约 4k token,rate limit 用得更快。
如果你像我一样开的是 Claude Max 5x,4k token/session 在 200K context 里只占 2%,但累积到一周可能多消耗几十万 token。如果你按 API 计费,这条路要好好算账。
第三条:治本,删掉冗余 skill 或精简 description。
我看了下我那 26 个 skill 里,有几个是早期试着装但其实没怎么用的(比如 layout-creator-workspace、json-canvas)。还有几个 description 写得过长(content-director 的 description 就拖了一长串”何时触发”的例子)。
把没在用的删掉、把长的精简下来,应该能让 1.8% 自然降回 1% 以下。
我个人倾向第三条 + 第一条组合:定期清理 + 长期不用的禁用。第二条留作”真要用到所有 skill 但短期”的备选。
这件事和昨天那篇 token saving 的逻辑是同一条
我昨晚写过一篇《Claude 1M 上下文一周烧了我 28M token》,里面专门有一节讲 CLAUDE.md 精简的逻辑:你在 CLAUDE.md 里写了什么,每一轮请求都把它当作 prefix 重新发一遍。12KB 的 CLAUDE.md 是 3K token,50 轮对话就是 150K token 重复发送。
skill listing 也是同一回事。
每个 skill 的 description 在 Claude Code 启动时进入 system prompt,整个会话期间这段内容会跟着每一次 API 请求被发出去。如果你装了 50 个 skill,每个 description 平均 500 字符,总长度就是 25KB(约 6K token)。一个 50 轮的会话就是 300K token 重复发送。
Anthropic 把这件事抬到 settings 层做 budget 控制,本质上是承认了”skill 越多越好”的假设是错的。每多一个 skill 就是每轮请求的固定成本。
这套机制和 prompt caching 是配套的。被加载的 skill description 进 cache prefix,cache hit 时只按 $0.30/M 计费。但被丢掉的 skill description 根本进不了 cache,所以那 22 个 skill 即使你把 budget 抬高到 2% 让它们都进去,也是命中 cache 之后才省钱,第一次写入还是按 $3.75/M 写的。
简单总结一句:skill 多到一定程度反而帮倒忙。每个 skill 的 description 都是每轮请求的固定成本,超过 budget 还会被默默丢掉,看起来装着但其实没在用。
我自己今天做的具体动作
读完这条 warning + 跑了 /doctor 之后,我做了三件事。
最先做的是把项目级和用户级 skill 各自做了一遍 review。
项目级(MyHexoBlog 的 .claude/skills/)8 个全部保留,因为这些 content-* skill 是这个博客创作 pipeline 必需的。
用户级 18 个里,我决定把 layout-creator-workspace、json-canvas、obsidian-bases 三个临时禁用。这三个分别是为某个一次性任务装的,最近 3 个月都没用过。禁用之后 ~/.claude/settings.json 里加 disabled 列表。
接下来把 content-director 那个我自己写的 SKILL.md 的 description 字段从 3 行精简到 1 行。原来的描述里把”何时触发”的例子写得很全(”帮我写一篇”、”写一篇关于 xxx”、”创建新文章”等等),现在只保留一句核心定位 + 一组关键 trigger。
最后那一步是关于 settings 的判断:我在 ~/.claude/settings.json 里没有抬高 skillListingBudgetFraction。理由是治本之后再看是否还触发 warning,没必要先付这 4k token/session 的固定开销。
跑完上面三步重启 Claude Code,warning 没再出现。说明 26 个 skill 经过精简之后总长度已经回到 1% 预算之内了。
还想问的几件事
最后留几个我自己没完全想明白的点。
/skills 这个命令的 UI 在 2.1.133 上看起来还很基础。它能显示每个 skill 的 description 长度吗?能显示哪些被丢了吗?能直接在 UI 里编辑 description 吗?我目前的体验是只能 enable/disable,看不到 description 详情,得回到 SKILL.md 文件去改。
如果 Anthropic 把”按使用频率自动调整 budget”做进 Claude Code 里,那 description 长度的优化就不是用户自己的责任了。这条机制理论上完全可以做:每个 skill 在过去 30 天的调用次数 → 自动给最常用的留 full description、给从没用过的只留名字。
skillListingBudgetFraction 默认 1% 是怎么定的?为什么不是 0.5% 或者 2%?官方文档目前没解释这个数字背后的考量。我猜是按”装 20 个左右普通 description 的 skill 不会触发”这个目标定的,但具体是不是这样我不确定。
评论区想问两件事。
跑 /doctor 看一眼你的 skill 状态,告诉我你装了多少个、丢了多少个?我猜大部分人在 30+ 这个量级会自然撞上这个 warning。
另外,你倾向哪条处理路径?我自己选了治本,但如果你是按 API 计费、又对 skill 调用稳定性要求很高的开发者,可能更应该抬高 budget。想听具体场景下的取舍。