800 MB 在 iPhone 上跑出 27 tok/sec,PocketPal 让我重新看本地 LLM

哈喽,我是飞飞。
我每天用 Claude Max $200/月 跑 Claude Code,平时根本不是本地 LLM 信徒。
但上周有两个场景把我推过去试 PocketPal:一个是飞机起飞前关 Wi-Fi 想继续写日记被打回原形,另一个是想用 AI 总结一份私密医疗记录但不想喂给云端。
我装了 PocketPal AI、下载了 Qwen3.5-0.8B q8_0、在 iPhone 15 Pro 上跑了 benchmark。
跑分截图里那个数字是 27.10 tok/sec。
写到这里前我又翻了一遍公开数据:iPhone 16 Pro 跑 3B 模型才 4 tok/sec,Snapdragon X Elite 跑 7B 才 5 tok/sec。我这个 27 tok/sec 是怎么来的?
先看 iPhone 15 Pro 跑出来的 27 tok/sec 是个什么量级
跑分截图里的核心数字有两个:PP 585.16 tok/sec 和 TG 27.10 tok/sec。
说人话就是:PP(prompt processing)是模型「读完你说的话」有多快,TG(token generation)是模型「往外蹦字」有多快。
人能感受到速度的主要是 TG 这个数。
27 tok/sec 体感约等于什么?
中文一个 token 通常对应 1.5-2 个汉字,27 tok/sec 大致是一秒蹦 40-50 个汉字。
我自己打字熟练大概一秒 5-7 字,模型这个速度是我打字的 5-10 倍。比常见的云端 GPT-4o 流式输出体感慢一档,但已经远超「能用」的门槛。
横向对比一下:
- iPhone 16 Pro 跑 3B 模型:4 tok/sec
- Snapdragon X Elite 跑 7B:5 tok/sec
- Pixel 7 Pro 12GB 跑 Qwen2.5 复杂代码:6-8 tok/sec
- iPad Pro M4 跑 13B:15 tok/sec(已是移动端最快档)
- iPhone 17 Pro 跑 Qwen 9B:18-20 tok/sec
我 iPhone 15 Pro 这个 27 tok/sec 之所以好看,主要是因为模型只有 0.8B。
模型越小越快是常识。真正值得反过来想的是:0.8B 在我手机里能干哪些事?
后面我会回到这条。
在 iPhone 上我用 App Store 装了 3 分钟就开始跑
iOS 这边几乎没难度。
打开 App Store,搜「PocketPal AI」(作者写着 Asghar Ghorbani),免费,iOS 15.1+ 起步。
iPhone 15 Pro 上我装完打开第一个画面是空白的「模型」页。
右下角点 +,弹出 3 个选项:从 Hugging Face 添加、添加本地模型、Add Remote Model。
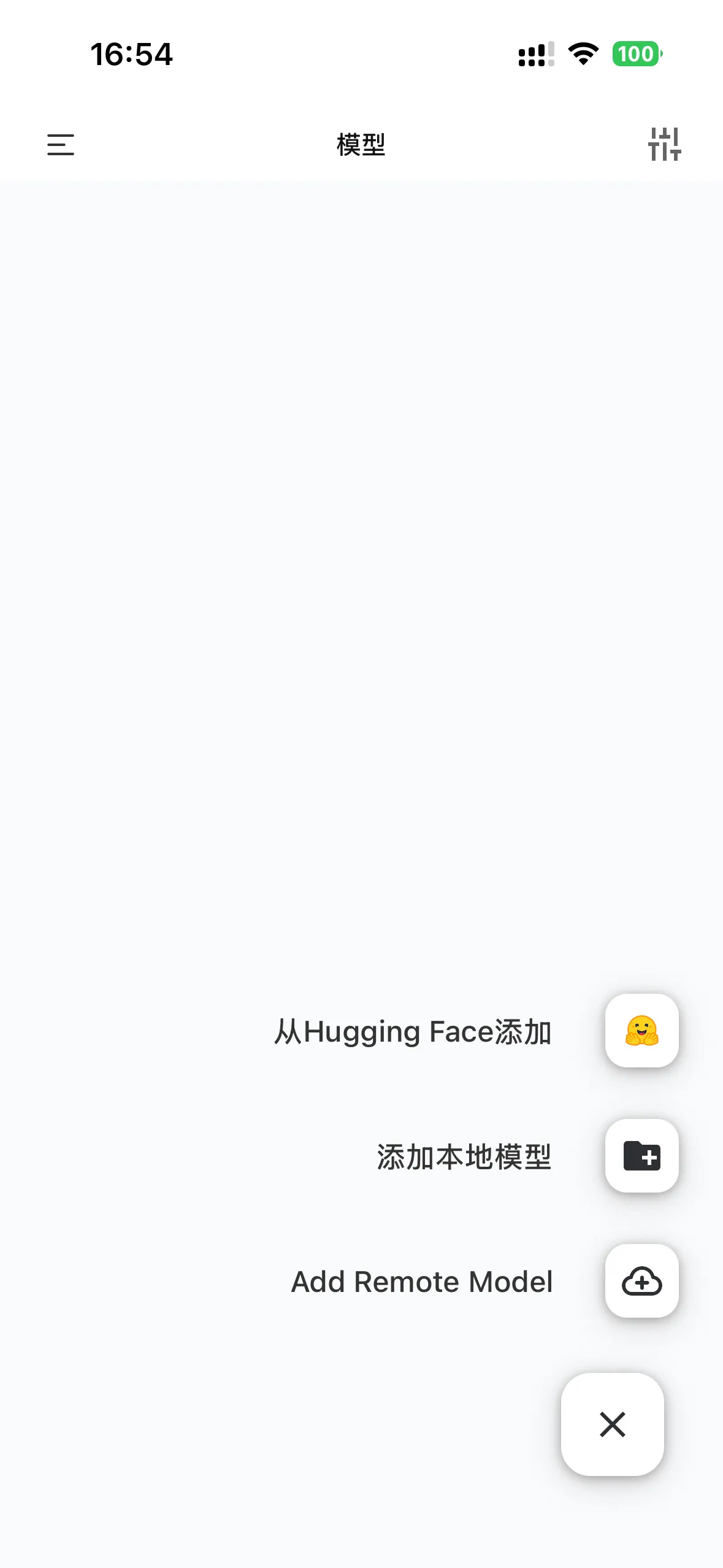
我选了「从 Hugging Face 添加」。
搜 Qwen3.5-0.8B,挑量化版本,按下载。这 800 MB 在 Wi-Fi 下大概 2 分钟搞定。
下载完点「加载模型」,跳到对话页就能聊了。
加起来 3 分钟,模型问一句「你好,请介绍下自己」就有答案:「我是由阿里巴巴集团旗下的通义实验室自主研发的『通义千问(Qwen)』系列大语言模型之一」。

模型自己说自己是 Qwen 系列,这一句话证明你装对了。
Android 这边推荐两条路:Google Play 稳但慢、GitHub APK 新但要点手动
Android 我没亲测,下面说的是 GitHub 项目和社区方法。
先说 Google Play 这条路:搜 PocketPal AI(包名 com.pocketpalai),开发者 LLM Ventures,免费下,要求 Android 7.0+,APK 98 MB。
Google Play 商店审核会让版本比 GitHub 慢几周,稳是稳,新功能等得久。
再说 GitHub Releases 直装这条路:去 github.com/a-ghorbani/pocketpal-ai/releases 拉最新版 .apk,手机开开发者选项允许「未知来源安装」,传过去点开装。
GitHub 直装的好处是版本快,能拿到 1.14.0 这种最新版(Google Play 这周还在 1.13.1)。
代价是要自己承担「APK 来源信任」,Google Play 那一层签名审核没了。
我自己如果是 Android 用户,会先 Google Play 试一周,确认能跑、能挑自己想要的模型,再考虑要不要切 GitHub 直装。
装好之后第一件事是挑模型,我跳过内置清单装了 Qwen3.5-0.8B
PocketPal 内置一份策展清单,里面常见的有:
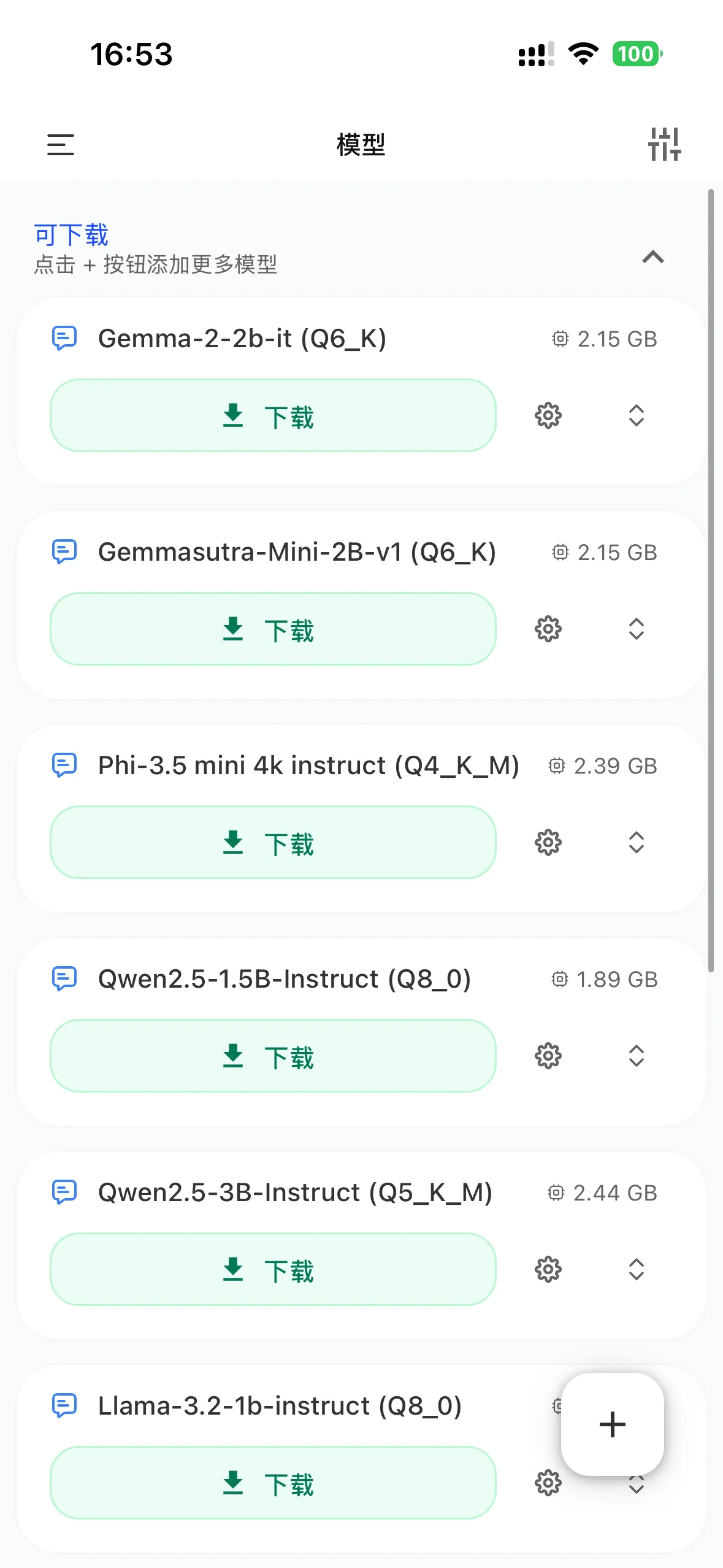
- Gemma-2-2b-it Q6_K · 2.15 GB
- Phi-3.5 mini 4k instruct Q4_K_M · 2.39 GB
- Qwen2.5-1.5B-Instruct Q8_0 · 1.89 GB
- Qwen2.5-3B-Instruct Q5_K_M · 2.44 GB
- Llama-3.2-1b-instruct Q8_0
我跳过这份清单,从 Hugging Face 单独装了 Qwen3.5-0.8B q8_0。原因有两个。
先说 Qwen3.5 这个版本。
阿里 Qwen3.5 系列 2026-03-02 发布,Small 档分 0.8B / 2B / 4B / 9B 四个尺寸,原生 256K context(说人话就是它一次能记住的对话长度上限是 25 万字左右)、支持 201 种语言,混合推理(small 档默认 reasoning 关闭,对小模型反而是好事,不会无限自说自话)。
PocketPal 内置清单里那几个 Qwen 是 2.5 老一代,落后一个版本。
再说 q8_0 这个量化。
gguf 是 llama.cpp 自家的二进制格式,说人话就是「方便手机加载的模型打包格式」。
q8_0 / q4_k_m 这些尾缀是不同的「压缩档位」:
- q8_0:8 bit 量化,文件接近原模型大小,精度损失最小
- q4_k_m:4 bit 量化,文件减半还多,精度有一定损失
- q5_k_m:折中档
iPhone 15 Pro 7.5 GB RAM 内存不算紧,0.8B 模型 q8_0 才 800.88 MB(后面 benchmark 跑分页能看到这个数),没必要为省内存换 q4 损失精度。
挑模型这件事的判断逻辑很简单:手机内存够、模型够小,就上最高保真的量化档。
benchmark 数字怎么读:PP / TG / 内存峰值这三个数翻译给小白
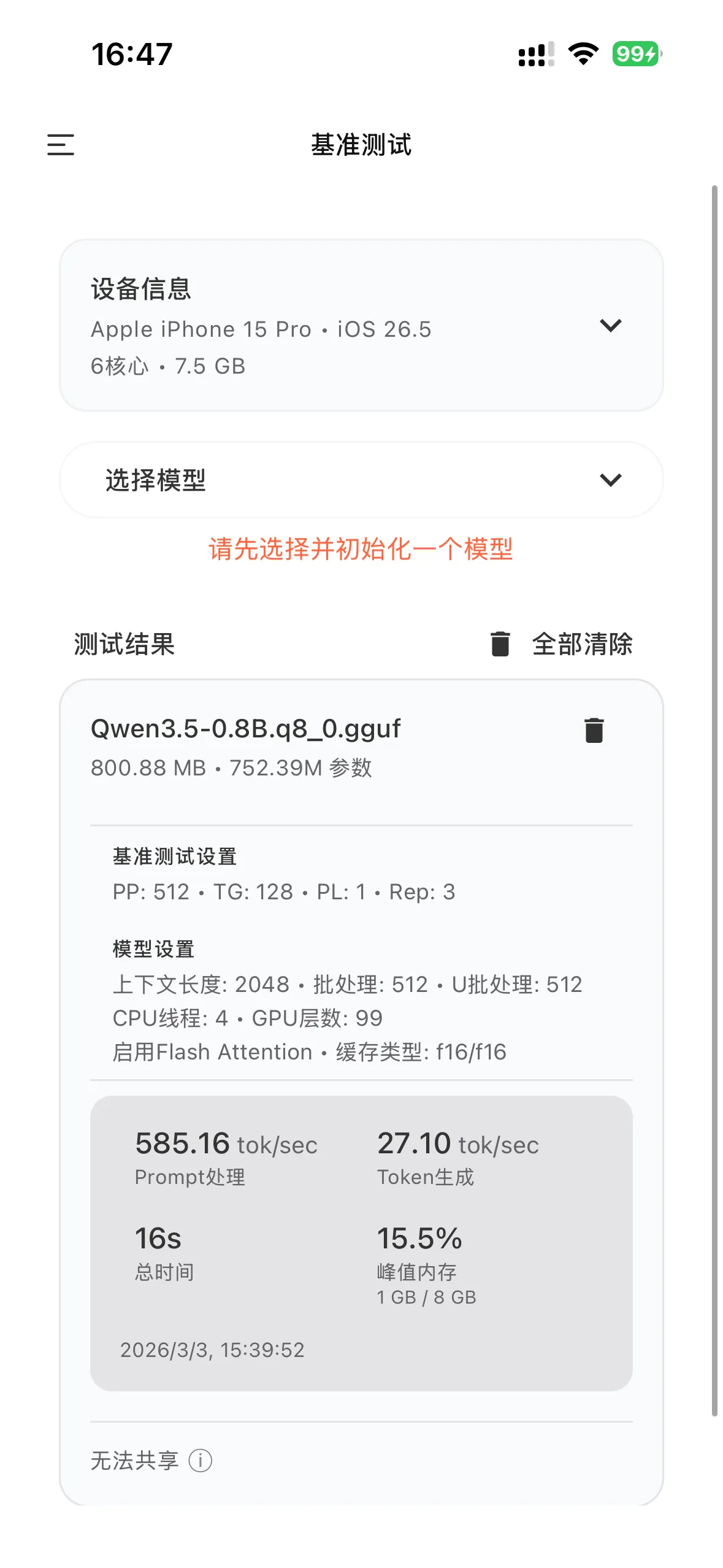
跑分截图里那一堆数字,对小白读者来说是天书。我翻译一下。
PP 585.16 tok/sec:模型读你输入的速度。说人话就是你贴一篇 2000 字的稿子进去,3-4 秒就吃完了。
对应使用场景:手机上让它读一篇长文章做总结,等待时间很短。
TG 27.10 tok/sec:模型往外蹦字的速度。说人话就是一秒打 40-50 个汉字。
对应使用场景:连续对话、写日记、翻译,都能跟得上你思考速度。
峰值内存 1 GB / 8 GB(15.5%):模型最多占了手机一成多内存。
对应使用场景:跑模型的时候你照样能开微信、刷推特,不会卡。
总时间 16 秒:跑完那个标准压力测试用了 16 秒,里面跑了 512 + 128×3 ≈ 900 个 token。
对应使用场景:基本上你只要不跑超长上下文,模型「热」起来的时间可以忽略不计。
模型设置里 GPU 层数 99、Flash Attention 启用 这两条要重点提一下。
GPU 层数 99 说人话就是「把模型全部塞到 GPU 上算」,iPhone 15 Pro 用 Metal 加速跑得动。
Flash Attention 启用说人话就是「用更省内存的注意力算法」,省内存的同时提速。
不开这两条的话,TG 我估计要掉到 15 tok/sec 上下。
飞机上写日记、隐私笔记总结,这两个场景我打算这样用
回到我最早装 PocketPal 的那两个具体场景。
飞机上写日记:从浦东到旧金山 12 小时无网,过去我只能拿手机记事本干写。
接下来准备这样做:起飞前在 PocketPal 里把 Qwen 加载好,开飞行模式,让它当我的「日记搭子」。
写到一半卡住了让它接两句,写完让它帮我标一下情绪关键词、按主题归类。
只要不联网,整个过程数据不出手机。这件事 Claude 做不了,因为 Claude 离线就死。
私密笔记总结:我前阵子拿了一份医疗体检报告,里面有具体指标。
我不想喂给 ChatGPT,也不想喂给 Claude 网页版(虽然 Claude API 默认不训练,但走网页输入这件事本身就要传)。
PocketPal + Qwen3.5-0.8B 这套,整个体检报告复制粘贴进去,让它讲讲哪几项偏高需要注意,全程关 Wi-Fi。
0.8B 的能力边界:写日记、做翻译、总结结构化文本、回答中等复杂度问题,体感都跟得上。复杂代码生成、长链路 agent 任务,0.8B 撑不住。
这就回到开头那条立场:本地 0.8B 跟 Claude Opus 比是输的,跟「飞行模式下没 AI」比是赢的。
电池、发热、模型库下载流量,这三个代价我装之前没意识到
聊完优点要诚实说代价。
电池:跑模型时 CPU + GPU 拉满。
我用 iPhone 15 Pro 连续问了 20 分钟,电量从 100% 掉到 88%。
按这个速率,一整段飞行 12 小时如果一直跑,电池撑不过 6 小时。实际用要节制:写几句、停一停,不要让它在后台一直推理。
发热:连续跑超过 10 分钟,机身明显发热。
iPhone 15 Pro 钛金属边框传热快,握着会烫。我建议放桌上跑,不要握在手里。
模型库下载流量:PocketPal app 才 98 MB,但模型动辄 800 MB - 2.5 GB。
第一次下载必须连稳定 Wi-Fi,蜂窝下载会让你看着流量计跳。
PocketPal 默认推荐的几个模型如果都试一遍,4-5 GB 起步。我建议挑一个稳定能跑的(比如 Qwen3.5-0.8B q8_0),其他先不下,等真的有场景再来。
Qwen3.5-0.8B 跟 Apple 自家 foundation models 摆一起怎么选,我还没想明白
iOS 26.5 自带 Apple Foundation Models(系统级,A17 Pro 芯片上跑),开发者可以通过 API 调用。
跟我装的 Qwen3.5-0.8B 摆在一起,理论上 Apple 自家那个跟 iOS 系统集成度更深、电池优化更好。
但 Apple Foundation 我还没看清楚的几个点:
- Apple 模型权重不公开,跑分官方没说具体数字
- 我自己没法换模型,跟着 iOS 系统升级走
- 第三方 app 调起来要走 Apple API,免不了走苹果生态
PocketPal + Qwen 这套给我的是另一种自由:随时换 Gemma、Phi、Llama 试,模型坏了我自己换。
代价就是上面说的电池、发热、流量。
留个问题给你:如果 iOS 27 的 Apple Foundation Models 性能能追到 Qwen3.5-0.8B 的 27 tok/sec,你还会装 PocketPal 吗?
或者反过来,你是为了「能换模型」这件事本身才装 PocketPal,还是只把它当一个能跑 LLM 的客户端?
评论区告诉我你的答案,我也告诉你我的。