OpenCode 把蚂蚁 1T 推理模型免费送你 7 天,但有条小字你得先看

哈喽,我是飞飞。
5 月 8 日凌晨,蚂蚁百灵团队发了一个新模型:Ring-2.6-1T。1 万亿总参数、63B 活跃参数、专门为 agentic 工作流(说人话就是给 AI 写代码、让 AI 调工具)调过的推理模型。
同一个凌晨,Novita Labs 把这个模型上架到了 OpenRouter,免费。
同一天,OpenCode(开源版 Claude Code,GitHub 90K+ star)把它加进自己的 OpenCode Zen 策展清单。
三方动作时间几乎卡在一起。免费窗口截止到 5 月 15 日 PT。今天是 5 月 11 日,还剩 4 天。
我下午装好 OpenCode 跑了一轮,准备写这篇之前想了一会儿。这条免费下面有一行小字,我看完之后没法装作没看见。
4/21 到 5/8 这 17 天里 AI 编程世界到底发生了什么
先把时间线还原一下。
4 月 20 日 GitHub Copilot 暂停个人订阅注册,第二天 4 月 21 日 Anthropic 把 Claude Code 从 $20 Pro 套餐页面下架。
我那一周已经写过一篇文章谈这件事。结论很直接:扁平订阅制 + agentic 工作流不兼容,烧不起。
时间走到 5 月 8 日。这一天我刷推刷出了三条公告,加起来构成那一整周最密集的中国 AI 动作。
DeepSeek 接 75 亿美金融资的消息先来,梁文锋自己掏 30 亿,中国 AI 创业公司有史以来最大单轮。
紧接着是 Anthropic Claude Code 团队工程师 Thariq 那条 9 个英文单词的推「HTML is the new markdown」,3 天 3.4M 阅读。
然后是这次的主角:蚂蚁百灵 Ring-2.6-1T 发布 + Novita 在 OpenRouter 上架免费端点 + OpenCode Zen 接入。
5/8 这一天不像巧合。看起来是 4 月那一周闭源订阅收紧之后,开源 + 中国推理模型 + 第三方推理云的对位反击。
我看着自己的 Claude Max $200/月账单,发现每一个 Anthropic 涨价的动作背后,都有人在给开发者准备 fallback。
Ring-2.6-1T 真正的卖点不在那个「1T」
「1 万亿参数」这个数字现在听起来已经不那么唬人了。DeepSeek V4-Pro 1.6 万亿、Kimi K2 1 万亿,Claude Opus 4.7 参数没公开但量级也在那里。1T 这个数字现在只算入场券。
那 Ring-2.6-1T 凭什么值得装个 OpenCode 来试?
我看了官方放的两个东西。
先说 active params 63B。说人话就是:模型总共有 1 万亿个参数住在那个大池子里,但每跑一次推理只激活 63B 实际参与计算。这是 MoE 架构的好处,让你跑得起这个量级的模型。
为对比,DeepSeek V4-Pro 1.6T 活跃 490B。Ring-2.6-1T 的活跃量是它的八分之一。意味着延迟和单 token 成本都低一档。这才是 OpenCode 这种「每秒可能跑几十次 tool call」的 agent 工作流真正需要的东西。
再说 adaptive Reasoning Effort。蚂蚁给它做了两档可调的「思考力度」:
high:偏 agent 和 tool use 场景,让模型快思考、多轮交互不卡xhigh:偏深度数学和科研推理,让模型慢慢想
你写 prompt 的时候可以指定。这跟 Claude 把 sonnet thinking 当个二选一开关不太一样,它给的是连续调节。同一个模型在不同任务上能切换工作模式。
我用 OpenCode 跑了几次。high 档下做 PR review,每次响应大概 8-12 秒回完。xhigh 在简单任务上明显比 high 慢两倍以上,但跟 Claude Opus 4.7 比并不显著快。说明 xhigh 是为难题留的档。
PinchBench 87.60 这个数字到底意味着什么
跑分这个事我最讨厌一段堆一堆。挑两个最有信号的说。
PinchBench 87.60(Ring-2.6-1T 的 high 档)。PinchBench 是个专门测 AI 在真实 agentic 任务里能不能跑通的跑分。
同档对比里,GPT-5.4 xHigh 比它低,Gemini-3.1-Pro high 比它低,Claude Opus 4.7x High 也比它低。
第一次看到一个中国开源模型在 agentic 跑分上压过当代旗舰闭源模型。PinchBench 本身也是 2025-2026 年才出现的新 benchmark,专门为 agent 时代设计,比 SWE-bench 那种几年前的老测试更贴近真实使用场景。
ClawEval 63.82。这是工具使用能力的跑分。Ring-2.6-1T 在这个 benchmark 上不是第一,但够用。说明它不是在某一两个跑分上磨过头,整体功能曲线比较平。
跟 4 月 21 日那时的体感对照一下:Claude Code 砍 Pro 的时候,开发者社区担心的是「中国模型还差一截,没得选」。5 月 8 日这个 PinchBench 数字第一次把这种担心打掉了一半。
但分数能用是一回事,跑起来好不好用是另一回事。
我今天下午装 OpenCode 把 model 切到 ring 跑了一轮 PR review
OpenCode 这个工具我之前断断续续在用。它是 SST 团队的开源 CLI coding agent,GitHub 90-95K star,定位是开源版 Claude Code,支持 75+ 个 LLM provider。
今天下午装最新版(如果你已经有可以跳过这段),配 OpenRouter API key,把默认 model 切到 inclusionai/ring-2.6-1t:free 这个端点。
我丢给它一个我之前用 Claude Opus 4.7 跑过的 PR review 任务。同样的 PR、同样的 prompt。
Ring 在 agent 模式下用了大约 4 分钟,吐出 6 条问题。Claude 那次是 3 条问题。
我对照看了一下:Ring 多发现的 3 条里,2 条是真问题(一处 nil 检查、一处异步 race),1 条是过度谨慎的误报。Claude 那 3 条都是真问题,但 Ring 抓到的那个 race 是 Claude 漏的。
256K context、$0 推理成本、抓到了 Claude 漏的一处 race。我盯着 OpenCode 终端看了一会儿。
短期内我不打算把 Claude Max 退订。Claude 在 plan 阶段的语义连贯性还是更稳一档,Ring 偶尔会绕路。
但作为第二意见、作为 sanity check 的二审、作为周末跑大批量 codemod 的算力补位,这套 free 端点的价值就出来了。
前提是你能接受下面这条「小字」。
OpenCode Zen 那行小字我没法装作没看见
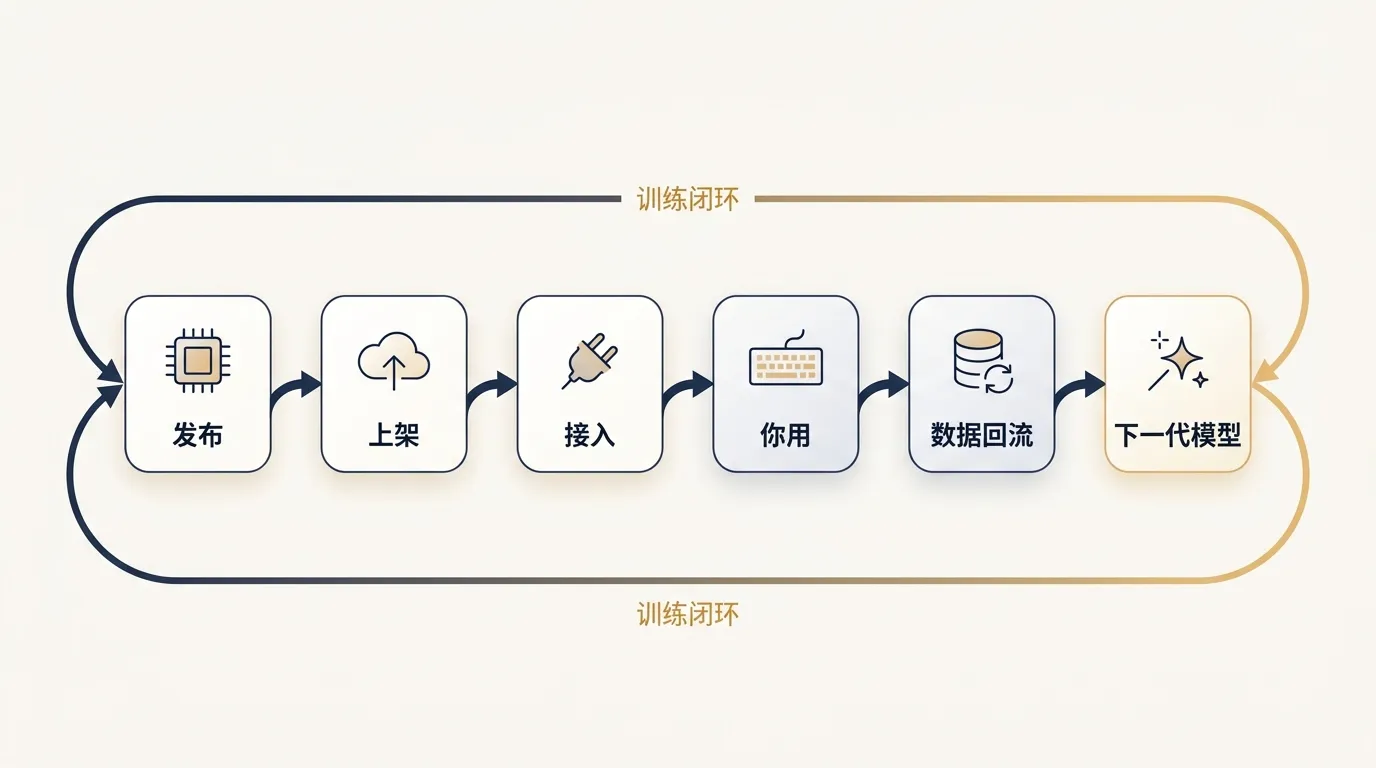
我去翻了 OpenCode Zen 的官方文档。在 Ring 2.6 1T Free 那一行下面,原文写着:
Ring 2.6 1T Free: During its free period, collected data may be used to improve the model.
翻成大白话:免费期间,你扔进去的 prompt 和代码,可能会被收集起来用于训练这个模型。
这条条款来自接入这个免费端点的默认设置,Novita 和 OpenCode 都没单独改过。
对比一下 Claude API:默认设置是「不用于训练」。这是 Anthropic 商业模式的核心承诺之一,也是为什么很多公司能拿 Claude 接生产代码。
如果你今天用 OpenCode + Ring free 跑了一个内部业务系统的 refactor、一个客户私有库的 PR review、一个公司核心算法的 spec,你的代码就有可能进入下一版 Ring 2.7 的训练集。
这条小字我反复看了两次。
它不是阴谋,是个公开的、写在文档里的交易:你用 4 天免费推理,蚂蚁拿到一周的真实 agentic 工作流数据。
对一家想训出更好 agent 模型的实验室来说,这周数据的价值远高于免费给你的那点推理成本。工程师作为决策者得知道这是 trade-off。
剩 4 天我自己分三种用法走
最值得做的是开个干净的沙箱仓库专门跑对照实验。同一个 prompt、同一个 PR、同一个 spec,对 Claude Opus 4.7 和 Ring-2.6-1T 跑双盲对比,把结果存下来。下次有人在群里问「Ring 真的有那么好用吗」,你手里有自己的数据。
再就是把你过去半年开源贡献过的那些 PR、那些 issue triage、那些个人项目代码,喂给 Ring 跑一遍。这些代码本来就在 GitHub 公开了,再被训练一次没什么额外损失。顺便看看 Ring 在你熟悉的项目结构上能跑到什么水平。
绝对不要做的事更直接:公司内部代码、客户私有库、未公开的算法、含真实凭据的脚本,不要直接喂给免费端点。
等 5/15 之后大概率会出付费版本(这是漏斗的下一站),那时候付费档大概率回到「数据不训练」的默认。
我自己今天下午用的就是前两种。第三种那块代码我搬了沙箱仓库才改写。
价格和开源 weights 这两件事,我等到 5/15 才能下判断
写到这里我手里还有两个问号。
一个关于 5/15 之后的价格。蚂蚁开源 Ling-1T 那次是真开源(model weights 上 Hugging Face)。Ring-2.6-1T 官方说「权重即将开源」,但「即将」是个浮动词。如果下周变成 OpenRouter 付费档而不是开源 weights,那就是另一种故事了。
另一个关于 OpenCode 把它放进 Zen 策展清单这个动作。OpenCode Zen 这一年里在做的事,看起来很像 Anthropic 早期的「Bedrock 中间层」:让你不用直接跟模型厂商打交道,OpenCode 帮你做模型选择。这对依赖 Claude Code 习惯的开发者是不是新的迁移路径,我现在还没想清楚。
留个问题给你:如果免费窗口 5/15 之后变成付费但价格只有 Claude Opus 4.7 的十分之一,你会从 Claude Code 迁过来吗?
或者反过来,那行「免费期间数据可能用于训练」的小字,会不会成为你拒绝迁的最后一条护城河?
评论区告诉我你的答案,我也告诉你我的。