Anthropic 工程师让 Claude 不写 Markdown 了,我突然不敢按 LGTM

哈喽,我是飞飞。
5 月 8 日 Anthropic 自己 Claude Code 团队的工程师 Thariq,在 X 上发了一条 9 个英文单词的推:”HTML is the new markdown.”后面跟了一篇《Using Claude Code: The Unreasonable Effectiveness of HTML》。
Thariq 自己披露这条推短短几天就跑到 3.4M 阅读、1.3 万收藏。Simon Willison 这种从 GPT-4 时代开始就默认让 Claude 写 markdown 的老用户,看完之后专门写了篇 link post 说自己准备改习惯。
但我今天不打算聊「Claude 该输出 markdown 还是 HTML」这种格式偏好的事。
我想聊的是另一件事:当 AI 输出越来越长、越来越结构化、越来越漂亮,工程师作为决策者的注意力到底还剩多少。
5/8 凌晨我刷到 Thariq 这条推时正在看 Claude 的 plan
那是个周五凌晨。我让 Claude Code 跑一个数据迁移的 plan,跑完吐出来一份 1500 行左右的 markdown,里面有 12 步、4 个表格、3 个 fallback 方案。我从头滚到尾大概用了 90 秒。然后我打开 X 准备睡觉,刷到了 Thariq 这条推。
Thariq 是 Anthropic Claude Code 团队的 Member of Technical Staff,前 YC W20、MIT Media Lab 出身,现在每天写 Claude Code 这个产品。他不是评论家也不是博主,他是每天用 Claude Code 跟 Claude 干活的一线工程师。
他在那篇短文里讲他自己已经几乎不让 Claude 写 markdown 了。所有的 plan、技术 spec、PR review、研究报告,他都让 Claude 直接输出 HTML,渲染成本地一个 .html 文件双击打开。配套他还放了一个 demo 站点 thariqs.github.io/html-effectiveness,里面有 20 多个 prompt 示例。
我盯着自己 9 秒前才滚完的那份 1500 行 markdown plan 看了半天。
他要解决的不是排版漂亮不漂亮的事
Thariq 写 HTML 的理由乍看是排版:HTML 自带表格、CSS 色块、SVG 图、JS 交互、in-page navigation。markdown 不行。
但他自己在文章里反复强调的不是这个。他说在 1M context 这一代模型上,Claude 一次能输出的 plan / spec / PR review 已经动辄几百行甚至上千行了。纯文本扁平结构在这个长度上撑不住。读者会从「认真读」滑到「快速扫」,从「快速扫」滑到「滚一遍」,最后进入「我相信你写得对」的状态。
他给出的对策很狠:把 Claude 的输出从「报告」升级成「工作台」。
举一个他自己的 PR review prompt 原话:”Help me review this PR by creating an HTML artifact… color-code findings by severity… render the actual diff with inline margin annotations.”翻成人话,就是 Claude 不再交给你一份 PR review 文档,它给你一个能筛严重度、能折叠章节、能在 diff 旁边贴评注的小工具,你在这个工具里复审 PR。
到这里都没问题。这是工程化思维,没毛病。问题是在「你在这个工具里复审」这一步。
上周二我让 Claude 出了一份 PR review,我滚了一遍就 LGTM 了
事情发生在 5/5 周二下午。我那天在带一个新人改一个内部计费服务,他提了个 PR 涉及一个金额计算的核心函数。我懒得自己一行行看,让 Claude Code 跑了 PR review 的 markdown,跑出来七个潜在问题,按严重度从高到低排好。我从头扫一遍,每条看了两秒钟左右,标了一个 LGTM。
第二天有人在 Slack 上 at 我,说那个函数的入参签名变了一个,下游一个老调用方今天早上挂了一次。我回去翻 PR,发现 Claude 那份 review 里其实在第四条提到了「该函数签名修改可能影响下游调用方,建议检查」,但是这条被它放在「中等严重」一栏里。我当时扫的时候,脑子已经默认前三条「高严重」是真问题,后面四条是补充。
事后我自己回想:我读 Claude 那份 markdown 的时候,注意力是层层下沉的,第一条用了 5 秒,第二条 3 秒,到第四条已经是「目光扫过」。我相信它的严重度排序是对的,所以我自己的判断从「逐条审」滑到了「分类抽样」。
写到这里我得承认一件事。Thariq 让 Claude 输出 HTML 工作台的那个工作流,我抄过来之后,不会比我那天读 markdown 的注意力曲线更好,甚至可能更差。
一个看起来已经被设计好的界面,会比 markdown 更难质疑
我后来去翻了几篇学术圈这两年讨论 AI 决策替代的论文,arxiv 2412.06593 这一篇做过一个实证:anchoring bias 在 LLM 上广泛存在,连推理模型都没幸免。这条研究本身关心的是 LLM 自己的认知偏差,但读者的偏差结构是对称的:你读 LLM 输出的时候,第一个出现的判断会成为你后续所有判断的锚。
我自己代入想了一下。读 markdown 的时候,至少版面是平的,第三条和第七条在视觉上没差别。换成 HTML 工作台之后,Claude 给你的是一个已经分好色块的界面:高严重度红、中严重度黄、低严重度灰;在 collapsible section 里折叠好;甚至还有一个左侧的 filter 让你「只看高严重度」。
这套界面已经替你做完了第一轮判断。等你点开它,你的决策从「哪几条是真问题」变成了「红色色块这几条要不要放过」。
更糟的是 MIT 的 Kosmyna 等人 2025 年做的一项 EEG 实验。他们让一组人在 4 次 session 里持续用 LLM 辅助写作,对照组只用搜索引擎或者纯靠脑子。4 次 session 后,LLM 组在跟推理和记忆相关的脑网络上的连通性显著下降。Microsoft Research 同年也发过一份调研,结论同向:高频 cognitive offloading 用户的批判思考评分反而最低。
这两份研究我看完,最不舒服的一句话来自 Microsoft 那份调研的结论:用 AI 越多的人,并不是因为他们的判断变得更好所以敢更多地依赖 AI。恰恰相反,他们是因为依赖了 AI,所以判断能力本身的肌肉在萎缩。
这循环我画在便签上,是三段路
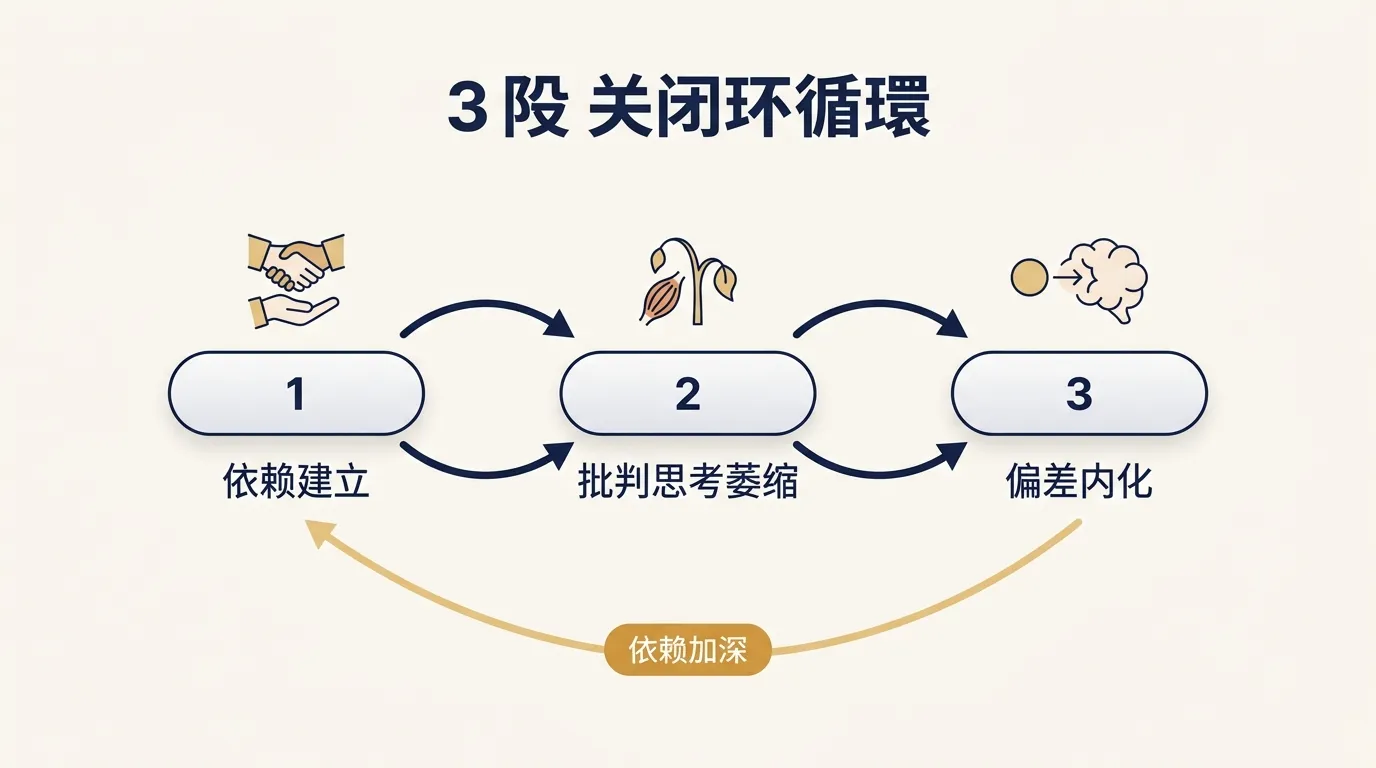
起点是 initial dependency。Claude 给的 plan 看起来很合理,你接受了。第一次接受可能是因为它确实做对了。再往后接受的速度越来越快,因为上次也没出问题。
中间这一段叫 critical thinking atrophy。一旦形成了「Claude 给的东西可以快速接受」的肌肉记忆,你逐行核对的肌肉就开始萎缩。这跟道德没关系。注意力是稀缺资源,大脑会自动找省力的路径走。
走到最后是 bias internalization。等萎缩发生之后,Claude 的某种偏好(比如把签名变更当中等严重度,或者把某种 fallback 方案当低优先级)会被你内化成你自己的偏好。再往后,哪怕没有 Claude 你做决策也会带上这个倾向。
我那天的 PR review 这件事,刚好走完起点到中段的过渡。最后那一段我还没走到,但我能感觉到风向在那个方向。
那 Thariq 这套工作流到底要不要抄
要抄,但抄之前我现在多了一个问题:我读这份输出,是为了「看完知道下一步怎么动」,还是为了「自己最终拍板」。
如果是前者,HTML artifact 是好东西。比如我让 Claude 帮我把过去一周的 GitHub issue 整理成一个可筛选的看板,目的就是导航和触发跟进,HTML 比 markdown 好用十倍。我也确实会拿 Thariq demo 站点里那几个 prompt 抄过来用。
如果是后者,我现在的偏好反而是退一步。让 Claude 给我纯文本,甚至是没有任何加粗、列表、严重度标记的 plain text。让信息回到一种「没有被预先排序过」的状态,强迫我自己做一次排序。我读得会慢,但慢就是目的。
这个判断对 PR review 这件事尤其敏感。我打算从这周开始把内部 PR review 的 prompt 改成「输出 plain text,不要分严重度,不要按重要性排序,按代码出现的物理顺序逐条列」。让 Claude 不替我做第一轮判断,把这个动作还给我。
30 天 LGTM 次数和会议纪要 prompt,是我现在最不敢动的两件事
先说 LGTM 这件事。过去 30 天里我给 Claude 输出的 plan 一共按过几次 LGTM、其中真的逐行看完的有几次,我打算这周末翻一下 Claude Code 的 session 历史去数。我现在的猜测是 LGTM 的次数会让我尴尬。
会议纪要那个事更具体一点。Thariq 那个 HTML demo 站点里有一类我特别想抄的 prompt 是「让 Claude 把 60 分钟的会议纪要做成一个可筛选 + 可生成 action item 的小工具」。这个 prompt 跑出来一定好用。我担心的事情很具体:它做得太好之后,我会更不去亲自看完会议视频。这件事我没想好怎么戒。
留个问题给你:过去一周你接受 Claude / Cursor / Copilot 给的 plan 的时候,平均每次会真的逐行看几行?如果你不数,那就是 0。
评论区告诉我你今天的真实数字,我也告诉你我的。