三年不要外部钱的 DeepSeek,第一次接 75 亿融资,梁文锋自己掏了 30 亿

大家好,我是飞飞。
5 月 8 日 The Information 抛出来一个数字:DeepSeek 准备接它成立 3 年来第一笔外部融资,总盘子 50 亿元人民币(约 75 亿美元),估值 500 亿美元。
这个数字本身已经够惊人。它是中国 AI 创业公司有史以来最大的一笔单轮融资。
但真正让我盯着屏幕看了好几遍的不是 75 亿这个数。
是另一个数字:在这 75 亿里,梁文锋本人要写其中最大的一张支票,金额大概是 20 亿元人民币(约 30 亿美元),占整轮的 40%。
而他在融资前已经持有 DeepSeek 89.5% 的股份。
一个持股 90% 的创始人,在公司第一次对外开放融资的时候,自己掏出近一半的钱。
这事在硅谷的剧本里我没见过。
创始人写最大支票,这件事的反常之处
按硅谷的标准看,这套操作是反着来的。
A 轮、B 轮的逻辑通常是:创始人用股权换外部资金,自己持股逐轮被稀释。Sam Altman 在 OpenAI 的非营利母公司里持股是 0;Dario Amodei 在 Anthropic 的股权也只有个位数百分比。这是常态。
DeepSeek 的剧本不一样。
梁文锋自己掏 30 亿美元意味着这一轮有 40% 的钱根本不是稀释他的股权,而是他用现金买下自己公司的新发行股份。融资完成之后他持股不会大幅下降,反而是公司账上多了 75 亿现金、外部投资人拿到 10% 出头的少数股权、他自己继续坐在 80% 多的位置上。
常规的”接受外部资金”是创始人拿股权换现金。梁文锋这次走的更接近”借助外部估值锚点 + 自己加注”的组合动作。
外部投资人这一轮拿到的不是控制权也不是大块股权,他们买到的是”和梁文锋一起站在 500 亿估值这条线上”的资格。
我看到这个结构的第一反应是:他不是缺钱。
缺钱不是这次融资的原因
DeepSeek 这家公司过去三年没接过一分外部钱。
它从 2023 年 7 月成立到 2026 年 4 月,所有运营资金都来自梁文锋自己创办的对冲基金 High-Flyer(幻方量化)的资产负债表。R1 那个让英伟达股价 1 月底单日跌 17% 的模型,训练成本据报告 600 万美元,这个钱当年全是 High-Flyer 内部出。
如果只是缺现金,他完全可以再从 High-Flyer 转一笔。事实上 4 月份他刚做过一次:往 DeepSeek 注册资本里又注入了一笔个人资金,让公司注册资本提升了 50%。
那么问题就成了:既然能继续自己掏钱,为什么这周还要走外部融资?
我自己看下来有几个层面在同时起作用。
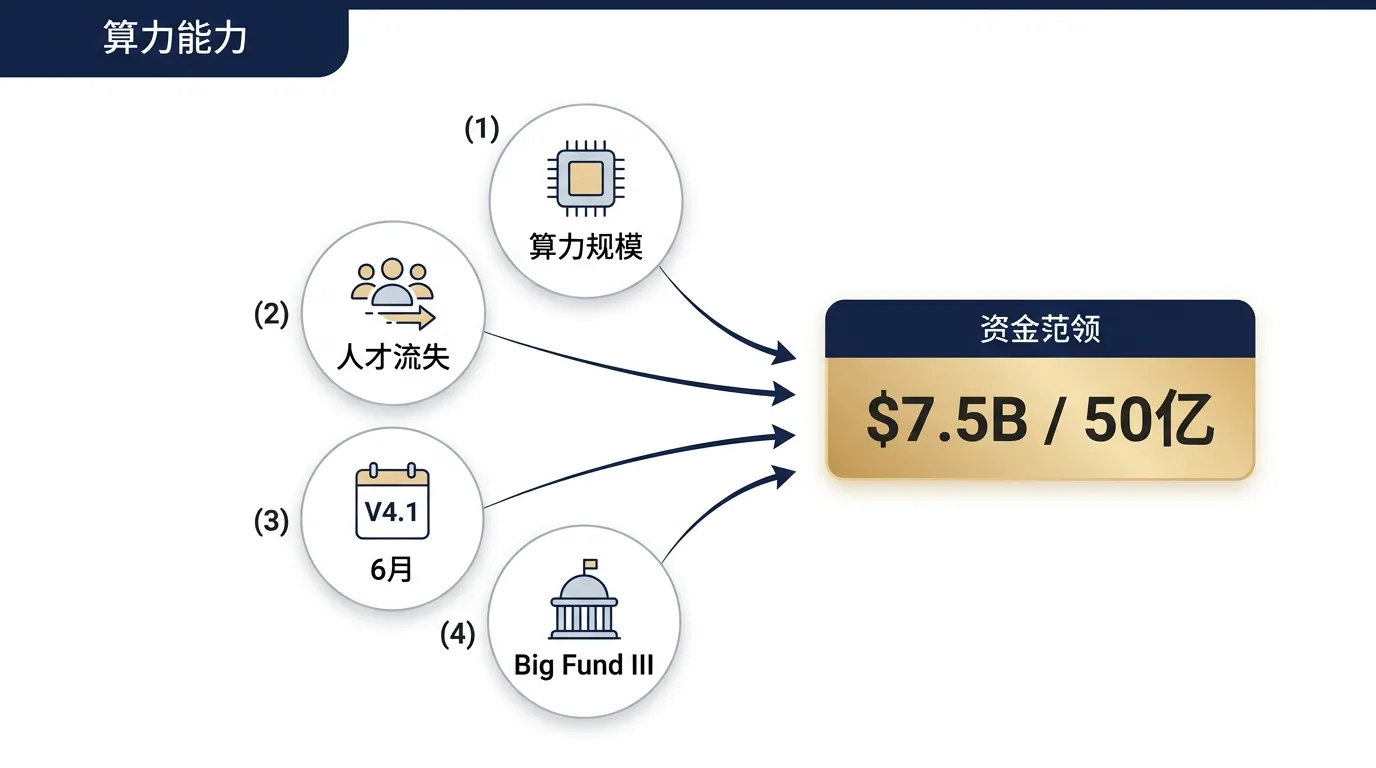
算力的账,对冲基金的资产负债表撑不下去了
先说算力规模。
R1 训练 600 万美元那种叙事,是 V2、V3 时代的事。到了 V4-Pro(4 月 24 日发的,1.6 万亿总参数、490 亿激活)这个量级,单次训练的算力成本已经不再是百万美元级,而是十亿美元级。1M context 训练 + 推理的 KV cache 摊销 + V4.1 在 6 月还要再来一次。
High-Flyer 2025 年的 AUM 据公开报道在 100 亿美元上下浮动。把这个体量的对冲基金 AUM 拿去支持一个每年烧十亿美元算力的 AI 实验室,逻辑上能撑,但风险敞口太集中。
外部融 75 亿美元相当于把 DeepSeek 这块业务的烧钱压力从 High-Flyer 资产负债表上剥离出去。
人才的账,3 年不发期权撑不住了
人才这一面我觉得更关键。
DeepSeek 过去三年最被外界讨论的一件事,是它的研究员团队几乎不接受外部猎头。这个反常的稳定性建立在一个隐含前提上:核心研究员相信”在 DeepSeek 做研究的体验本身值得”。
到 2026 年这个前提开始动摇。
The Paper(澎湃新闻)4 月份做过一份 DeepSeek 人才流失盘点,确认核心贡献者陆续被 Tencent、ByteDance、小米、DeepRoute.ai 这几家挖走。原因不复杂:ByteDance 给 staff researcher 的 package 已经飙到 800 万人民币 base + 大量股权激励;DeepSeek 既没有发过期权也没有公开 IPO 路径。
研究员留下来的代价是机会成本越拉越大。
这一轮融资 TechCrunch 引用的内部说法之一就是 “to offer employees shares in the company”,对应的中文意思是给员工发股权。500 亿美元估值这个数字一旦坐实,DeepSeek 就具备了发一份”500 亿对标”期权 package 的能力,把核心研究员的纸面身价直接锚在和 Tencent/ByteDance 同一条线上。
这是这轮融资真正解决的问题。
V4.1 在 6 月,钱要在那之前到账
产品节奏是另一条线。
DeepSeek 在 4/24 发了 V4-Pro 和 V4-Flash 两个 preview 模型,但是 V4 系列后续的重头戏 V4.1 据 Pandaily 报道安排在 2026 年 6 月。
V4 preview 已经把 1M context 这个能力做出来了,V4.1 据传要把推理质量再往上推一档,对标 GPT-5.4 / Claude 4.5。这种级别的训练 + 推理基础设施要的是一次性的大额投入,分摊到月度运营成本里消化不掉。
这轮 75 亿如果按时间窗算,正好赶在 V4.1 发布前到账。
钱进来的节奏比钱本身的金额更说明问题:DeepSeek 从一家”训练好模型再发”的实验室,正在变成一家”按节奏迭代产品 + 同步扩张算力”的常规公司。
Big Fund III 进来这件事的政治信号
外部领投方是中国国家集成电路产业投资基金第三期(Big Fund III)。
这只基金过去十年主要投半导体,比如 SMIC、长江存储这条线。它历史上投 AI 软件公司的次数屈指可数。这次主导一家 AI 实验室的首轮融资,是国家级资本第一次显式给 DeepSeek 背书。
把它和 Tencent / Alibaba 跟投放一起看,信号是清晰的:北京希望 DeepSeek 成为中国 AI 产业出海的旗舰,而不是一个偶尔放出爆款论文的研究项目。
这个判断对 DeepSeek 自己未必全是好事。它过去能走 Apache 2.0 / MIT 开源路线、走 R1 那种学术化的”我们追求 AGI”叙事,前提之一就是它没有外部资本要回报。
Big Fund III 进来之后这条路会变窄。下一阶段做模型选型、做模型权重发布策略的时候,背后多了一个国家级 LP 在看。
跟着 OpenAI / Anthropic 走那条路的代价
The Information 这篇报道里有一句话最值得反复读:DeepSeek 这次募资的资金用途之一是 “plot revenue efforts”,意思是开始规划营收。
把这件事放进 OpenAI 和 Anthropic 这两年的轨迹里看,就特别清楚。
OpenAI 从 GPT-3 发布到 ChatGPT 商业化中间隔了大约 2 年;从 ChatGPT 商业化到 ChatGPT Enterprise 大约 1 年。Anthropic 从 Claude 1 公开到 Claude for Enterprise 节奏类似。两家的共同特征是:模型领先 → 企业产品 → 现金流转正 → 再融资 → 算力扩张。
DeepSeek 走过的是另一条路:模型领先 → 不商业化 → 内部对冲基金供血 → 走开源吸引开发者。
5 月 8 日的报道意味着这条路被替换掉了。从这周开始它要走 OpenAI / Anthropic 那条路。
代价是什么?
代价是 R1 那种叙事不再成立。R1 当时被全球反复引用的核心叙事其实只有一句话:600 万美元做出了 GPT-4 级别。”模型本身很强”反而是从属的那一面。这个叙事能成立的隐含前提是:DeepSeek 是一个非商业的研究组织,所以可以选择不投入巨资。
500 亿美元估值 + 75 亿融资 + 企业产品规划之后,下一次 V4.1 / V5 发布如果再说”我们用了 X 万美元做出了 GPT-5.4 级别”,舆论的对照系会自动切换:你是个 500 亿美元估值的公司,不是当年那个独立研究室。
判断这件事的好坏意义不大。它说明的是 DeepSeek 这家公司正在从一种叙事身份切换到另一种身份。
90% 持股这件事可能是关键
回到开头那个数字。
我现在重新想梁文锋自己掏 30 亿、保留 90% 持股这个动作的目的,越想越觉得它不只是”founder conviction”那么简单。
他在用现金买下一件具体的事:哪怕拿了 Big Fund III 和 Tencent / Alibaba 的钱,DeepSeek 这家公司接下来 5 年的方向决定权,依然在他一个人手里。
如果他持股是 30%、40% 这种区间,那么外部投资人加 Big Fund III 加员工期权池组合起来就有可能在董事会层面对他形成制衡。
但是 90% 是另一回事。90% 之后哪怕融资稀释 5%、再发期权池稀释 5%,他还在 80% 多。无论他要把 V5 走开源还是闭源、要把企业产品做成 SaaS 还是 API、要把 DeepSeek 卖给 Tencent 还是独立 IPO,董事会层面没人能否决他。
这一轮真正交易出去的东西其实不在股权层面。它在另一个层面:DeepSeek 接下来 5 年的剧本由谁写。
外部投资人接受这个交易,因为 500 亿估值在 2026 年的中国 AI 市场里几乎是唯一一张能买到顶级研究员团队 + V4 / V4.1 / V5 路线 + 全球开源声誉的票。
还想问的几件事
留几个我自己也没盯清楚的问题。
钱的来源是一个。梁文锋这 30 亿美元从哪来?High-Flyer 的资产负债表本身公开数据有限,AUM 在 100 亿美元附近浮动。如果这 30 亿是他从 High-Flyer 个人收益里抽出来的,意味着他过去 7 年在量化交易上的累积收益已经足够覆盖这种量级的现金支出。这本身就是另一个值得单独写的故事。
V4.1 的发布节奏是另一个。V4 preview 是 4/24 发的,V4.1 如果按 6 月节奏推,中间窗口只有 6-8 周。这个节奏对标 OpenAI 大概是 GPT-5 到 GPT-5.1 的间隔。DeepSeek 真的能撑住这种发版速度吗?还是 V4.1 会和这轮融资一起被推迟到 Q3?
企业产品到底长什么样我也很想知道。DeepSeek 一直没有正式的 ToB 产品线。这次说要 “plot revenue efforts” 我猜是 API 收费 + 企业部署 + 行业定制三条线,但还没看到任何落地细节。如果你在企业 IT / 采购岗位上,DeepSeek 的销售团队最近联系过你吗?我很想知道他们的对外口径。
评论区聊聊。你觉得 DeepSeek 这一轮 75 亿之后,会不会重蹈 OpenAI 那条”越融资越远离原始使命”的路?还是说梁文锋持股 90% 这一道护城河足够把这事按住?