小米也开源了终端编程助手,我拿它跟天天用的 Claude Code 真打了一轮

哈喽,我是飞飞。
昨天刷到一条消息:小米开源了一个叫 MiMo Code 的终端编程助手,自报跑分超过 Claude Code,还限时免费。
我第一反应又是「这周第几个屠榜的」。这两年国产工具隔三差五甩一张「超越 Claude」的对比图,看多了我手指头条件反射就往上划。
但这条我没划走。因为我天天用的就是 Claude Code,它把矛头直接戳到我饭碗上了。于是我做了件跟以往不一样的事:没光看跑分,我把它装进终端,真扔了个活给它干,全程盯着,最后自己又复核了一遍。
结论先撂这儿:它初稿确实会写错,错得还不轻,但它能自己把自己的错兜回来。这一点,比那张跑分图值钱多了。
那张「62 比 57」的跑分表,到底信不信得过
小米给的核心数字是这样的:同一个 MiMo-V2.5 模型,分别塞进 MiMo Code 和 Claude Code 两套壳子里跑,SWE-Bench Pro 拿到 62% 对 57%,Terminal Bench 2 拿到 73% 对 68%。两边都领先大概 5 个百分点。
这个讲法其实挺聪明。它没说「我模型更强」,它说的是「同样的模型,我这套调度系统能多榨出 5 分」。换句话说,比的是脚手架的工程,不是参数表。这个角度,我服。
但有个坑得先给你刨出来。这些分全是小米自己在自家机器上跑的,MiMo Code 到现在还没出现在 SWE-Bench Pro 和 Terminal Bench 2 的官方榜单上。自己关起门跑的数字,跟别人按官方流程提交的成绩去横着比,中间隔着一层配置口径的差。
这个亏我上个月写 MiniMax M3 刚吃过。榜上风光和日常顺手,是两码事。所以这次我学乖了,不光看它怎么说,我得看它怎么干。
装进终端这一步,我先踩了个坑
安装是真快。一句 npm install -g @mimo-ai/cli,十秒钟装好,终端敲 mimo 就起来了,界面全中文。它还有个「从 Claude Code 一键导入」,我点了一下,它真把我本地 44 个 Claude Code 配置扫了进去、同步了 5 个。这条不是吹的。
然后我就栽了。我图省事,直接用非交互模式 mimo run 把任务一股脑喂进去,结果它卡死在那儿,整整 14 分钟零输出,连个报错都没有。我一度以为是网络挂了。
扒了半天日志才看明白:它那个免费的匿名通道,得先跑一次把临时令牌「铸」出来,才能正常调模型。我手动跑了一遍 mimo providers login 选上免费通道,令牌一到位,再发同样的请求,11 秒就回我了。
这个坑不致命,但它暴露了一件事:免费午餐的门是虚掩着的,你得先用手推开一下。文档里没把这步标红,新手大概率跟我一样先撞个满怀。
让它真写个东西,第一轮就翻车了
通道通了,我给它派了个不大不小的活。
让它写一个零依赖的 Node 命令行工具,读一个 Markdown 文件,把开头那段 YAML frontmatter 解析出来,输出成 JSON。我特意点名要它支持两种写法:一种是 title: 值 这样的标量,一种是 tags: 下面跟一串 - 列表项。顺带让它自己写测试,跑 node --test 验过再交。
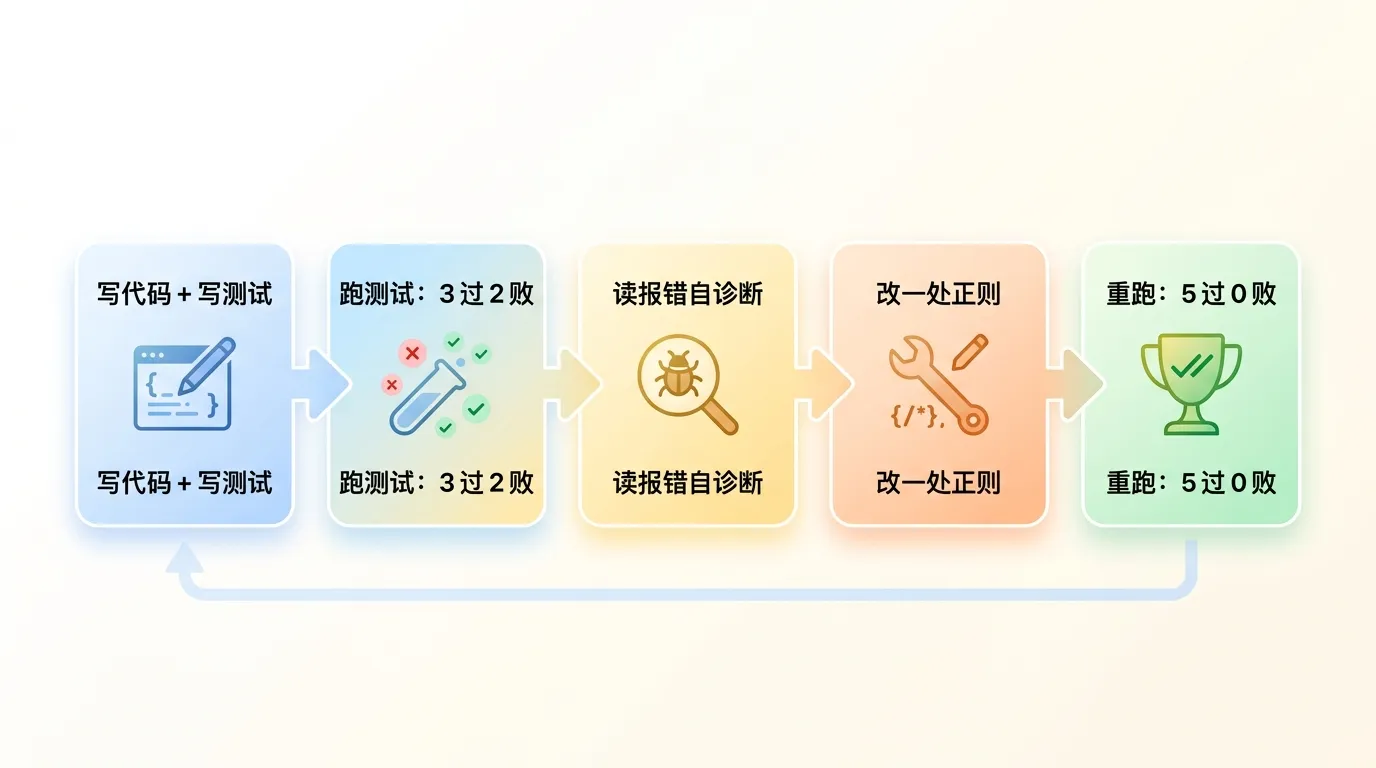
它全程自己干,没要我插手,大概五六分钟,写完了 mdfm.js 和一个测试文件,自己跑了测试。
第一轮结果:5 个用例,过了 3 个,挂了 2 个。
挂的那两个,全卡在列表解析上。我点开它写的代码一看就乐了。它那个匹配标量的正则,把 tags: 这种后面是空的行也一把抓走了,直接把 tags 赋成了空值。等下面 - javascript、- node 这些列表项过来,已经没人接它们了。最后 tags 出来是个 null,根本不是数组。
这是我点名要的两种写法之一,它就这么挂了。典型的「看着像写完了,核心需求其实是瘸的」。要是个新手把这代码直接交上去,跑通了标量就以为大功告成,列表那条路埋的雷得等线上炸。
但它转头把自己挖的坑自己填了
要是故事到这儿就完了,那这篇我大概又是「跑分好看、上手拉胯」的老调子。
但它没停。它读完测试那份失败报告,自己开口诊断了一句,原话是「这个标量正则把 tags: 匹配走了、还在列表项处理之前就把它设成了 null」。这句判断,跟我刚才趴在代码上看出来的,一个字都不差。
然后它动手改。就改了那么一处正则,把贪婪匹配空值的口子收紧,让 tags: 这种空行不再被标量分支吃掉。改完重跑,5 个用例全绿。
我没全信它自己报的「通过」。我把它生成的测试又独立跑了一遍,确实是 5 过 0 败。我还另起一个真实的 Markdown 样例文件丢给它的工具,标量的 title、列表的 tags、单字段提取,全对。
这一下我对它的观感就变了。它的价值压根不在「一把就写对」,新手都做不到一把写对。它的价值在那条闭环:自己写测试,测试反过来抓出自己的 bug,读着报错自己定位、自己改、自己再验一遍。它赌的不是手稳,是摔了能爬起来。这套东西,恰恰是 AI 写代码最缺的那块。
它的聪明,大半是 Claude Code 趟过的路
冷静下来再看,MiMo Code 那些让我眼前一亮的设计,很多我都眼熟。
它有个叫 Goal 的机制,你给它定个「测试全过且代码已提交」的收工条件,它每次想停手,系统就单拉一个裁判模型,拿完整记录核一遍条件是不是真达成了,专门治 AI 那种「干一半就说我做完了」的乐观毛病。这个思路,跟 Claude Code 的 /goal 命令是一个路数。
它还有个叫 Dynamic Workflow 的东西,让主模型生成一段脚本在沙箱里确定性地跑、用代码控制并发扇出。官方文档自己白纸黑字写着,这玩意「兼容 Anthropic Dynamic Workflow 的核心语义」。说白了,它没藏着掖着,明说了是照着 Anthropic 那套抄的。
再加上它整个壳子是基于开源项目 OpenCode 二次开发的,终端界面、插件、各种协议支持都是继承来的。所以拆开看,MiMo Code 大致等于:一个成熟的开源底座,加上几条 Claude Code 早验证过的长任务设计,再配一个限时免费的国产模型和全套中文汉化。
这正是它最精明的地方,也正是我得给自己泼盆冷水的地方。它把对的东西凑到了一块儿,这是真本事。但「凑得好」和「我该把主力搬过去」,是两本不一样的账。
顺带提一句,它吹得最响的「无限上下文」,实话讲也得撕掉点营销滤镜。它的窗口并没有真的变无限。实际做法是,趁上下文才用到两三成、四五成的时候,提前派个后台小工把状态写进文件,等窗口快满了再拿这些文件把现场重新搭起来。这套工程做得扎实,可本质上是「外置状态加重建」,离物理意义上的无限还差着远。
谁现在就该装,我自己又换不换主力
先说谁现在就该去装一个。
你要是想白嫖一个一百万上下文的国产模型练练手,或者就馋一个全中文、能从 Claude Code 平滑搬过去的终端 Agent,那别犹豫。免费,开源协议宽松,装一个放手边没坏处。它那条自我修正的闭环,值得你亲眼看一次。
再说我自己换不换主力。暂时不换。
我那条写文章的流水线,光 skill 就挂着十几个,拉资讯的、查重的、配图的、发公众号的,每一个都是照着 Claude Code 认配置、调钩子的脾气一点点磨出来的。真把底座换了,这些工具吐格式十有八九会飘,光把那套防 AI 味的规则重新调顺,就得搭进去好几个晚上。这笔迁移成本,省模型钱的账上从来不记。
但我得诚实补一句,这次的观感跟上次写 MiniMax M3 真不一样了。上次我是隔着跑分图站在岸上喊话,这次我是亲眼看着它栽进坑里、又自己爬出来的。
而且我也得把话说圆。我这回测的是个小活,五六分钟的量级。MiMo Code 真正吹的是「两百步以上的超长任务」,官方那份覆盖 576 个开发者的双盲测试也说了,活短的时候两边胜率五五开,得活儿长到两百步往上,它才把胜率拉到 65% 以上。
那条头条,我这个小任务压根没碰到。等我攒个够大的活,再单独拉它出来溜一圈,到时候摆效果给你看。
你现在主力用的是哪个?要是让你拿一个真实项目去考一个新的编程 Agent,你最担心它在哪一步掉链子?评论区聊聊。